
Attention in Neural Networks - 24. BERT (3) Introduction to BERT (Bidirectional Encoder Representations from Transformers)
03 Feb 2021 | Attention mechanism Deep learning Pytorch BERT TransformerAttention Mechanism in Neural Networks - 24. BERT (3)
In the previous posting, we had a close look into unsupervised pre-training and supervised fine-tuning, which are fundamental building blocks of BERT. BERT essentially improves upon state-of-the-art developments in pre-training and fine-tuning approaches. If you were able to follow concepts and ideas so far, it will be much easier to understand the details of BERT, which will be elaborated in this posting.
Unsupervised pre-training
The objective of pre-training in unsupervised fashion is similar to that of embedding methods such as Word2vec and GloVe.
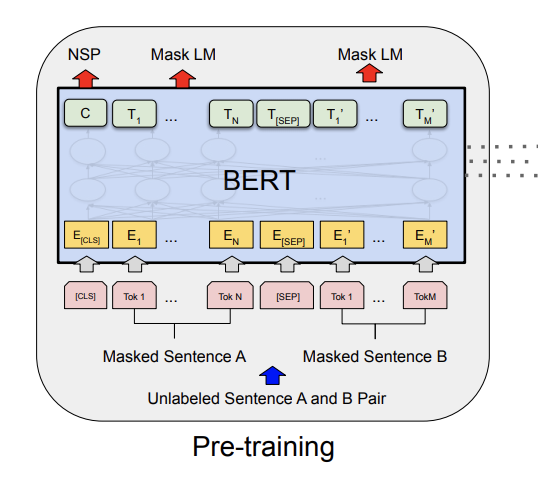 [Devlin et al. 2019]
[Devlin et al. 2019]
Similar to word embedding methods, vector representations of word and sentences are learned while performing two unsupervised tasks, namely masked language model (LM) and next sentence prediction (NSP).
Masked language model
Conventional LMs such as “bidirectional” recurrent neural networks are not truly bidirectional since they learn in one direction at a time, e.g., right-to-left or left-to-right. To overcome this and obtain deep bidirectional representations, BERT is pre-trained with a masked LM procedure, or the cloze task. The procedure is quite simple - some percentage of the input tokens are “masked” at random and predicted by the model. In a sense, it is similar to a “fill-in-the-blank” question, in which words to fill in are chosen at random. For instance, assume that we have an input sentence “To be or not to be, that is the question” and two tokens, not and question are masked. Then, the input and target sentences are:
Input: “To be or [MASK] to be, that is the [MASK]”
Output: “To be or not to be, that is the question”
In the paper, it is mentioned that tokens are masked with the probability of 15%. For more information on masked LM and Python (Keras) implementation, please refer to this posting
Next sentence prediction
The masked LM procedure models relationships between tokens. However, it does not capture relations between sentences, which can be critical for many downstream tasks such as question answering and natural language inference. NSP is essentially a binary classification task. For an arbitrary sentence pair A and B, the model is pre-trained to classify if the two sentences are adjacent (“IsNext”) or not (“NotNext”) - 50% of the time, B is actually the next sentence in the corpus and the other 50% of the time, it is a random sentence chosen from the corpus.
Supervised fine-tuning
Supervised fine-tuning is carried out in a similar manner to previous methods such as ULMFit. The task-specific inputs and outputs are plugged into the pre-trained BERT model and all the parameters are trained end-to-end. The authors show in the paper that pre-trained BERT outperforms state-of-the-art methods in various end tasks including natural language understanding and question answering.
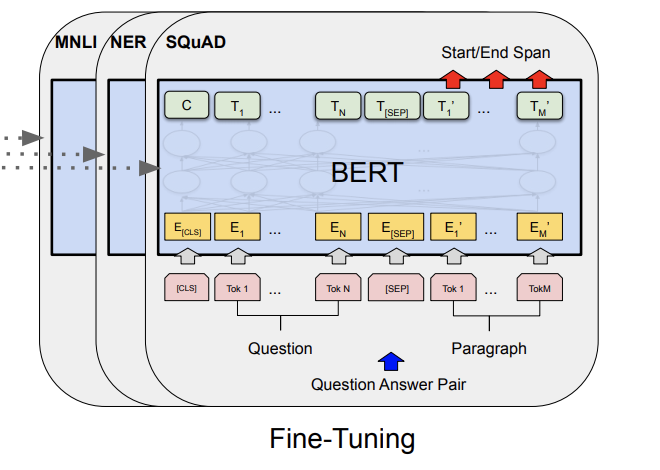 [Devlin et al. 2019]
[Devlin et al. 2019]