
케라스와 함께하는 쉬운 딥러닝 (5) - 뉴럴 네트워크의 학습 과정 개선하기
24 Apr 2018 | Python Keras Deep Learning 케라스다층 퍼셉트론 5 (Improving techniques for training neural networks 2)
Objective: 인공신경망 모델을 효율적으로 학습시키기 위한 개선 방법들에 대해 학습한다.
- 배치 정규화(Batch Normalization)
- 드랍아웃(Dropout)
- 앙상블(Model Ensemble)
지난 포스팅에서 뉴럴 네트워크의 학습 과정을 개선하기 위한 방법으로 가중치 초기화, 활성함수, 최적화에 대해서 알아보았다. 세개 다 최근 10년 간 인공지능 연구자들이 꾸준히 연구해온 분야이며, 괄목할 만한 발전이 있었던 분야이다. 이번 글에서 알아볼 세 가지 방법(배치 정규화, 드랍아웃, 모델 앙상블)도 매우 중요한 개념이며 현대 인공 신경망 모델의 필수적인 요소이다.
MNIST 데이터 셋 불러오기
# 케라스에 내장된 mnist 데이터 셋을 함수로 불러와 바로 활용 가능하다
from keras.datasets import mnist
import matplotlib.pyplot as plt
(X_train, y_train), (X_test, y_test) = mnist.load_data()
plt.imshow(X_train[0]) # show first number in the dataset
plt.show()
print('Label: ', y_train[0])

plt.imshow(X_test[0]) # show first number in the dataset
plt.show()
print('Label: ', y_test[0])

데이터 셋 전처리
앞서 언급했다시피, MNIST 데이터는 흑백 이미지 형태로, 2차원 행렬(28 X 28)과 같은 형태라고 할 수 있다.

하지만 이와 같은 이미지 형태는 우리가 지금 활용하고자 하는 다층 퍼셉트론 모델에는 적합하지 않다. 다층 퍼셉트론은 죽 늘어놓은 1차원 벡터와 같은 형태의 데이터만 받아들일 수 있기 때문이다. 그러므로 우리는 28 X 28의 행렬 형태의 데이터를 재배열(reshape)해 784 차원의 벡터로 바꾼다.
from keras.utils.np_utils import to_categorical
from sklearn.model_selection import train_test_split
# reshaping X data: (n, 28, 28) => (n, 784)
X_train = X_train.reshape((X_train.shape[0], -1))
X_test = X_test.reshape((X_test.shape[0], -1))
# 학습 과정을 단축시키기 위해 학습 데이터의 1/3만 활용한다
X_train, _ , y_train, _ = train_test_split(X_train, y_train, test_size = 0.67, random_state = 7)
# 타겟 변수를 one-hot encoding 한다
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
(19800, 784) (10000, 784) (19800, 10) (10000, 10)
배치 정규화(Batch Normalization)
간단히 얘기해서 배치 정규화는 인공신경망에 입력값을 평균 0, 분산 1로 정규화(normalize)해 네트워크의 학습이 잘 일어나도록 돕는 방식이다. 앞에서 자세히 설명을 하지는 않았지만 배치(batch)는 가중치 학습을 위해 경사하강법(gradient descent)을 적용할 때 모델이 입력을 받는 데이터의 청크(즉, 일부 데이터 인스턴스)이다.

케라스에서 모델을 학습할 때 fit()함수를 적용할 때 설정하는 batch_size 파라미터는 바로 이 데이터의 청크의 크기(개수)를 의미한다. 예를 들어 batch_size를 32로 적용하면 모델이 데이터 인스턴스를 32개 본 후에 가중치를 업데이트하는 것이며, 배치 정규화를 적용하면 각 32개의 데이터 인스턴스가 feature별로 정규화된다.
케라스에서 배치 정규화는 하나의 레이어(BatchNormalization())처럼 작동하며, 보통 Dense 혹은 Convolution 레이어와 활성함수(Activation) 레이어 사이에 들어간다.
모델 생성 및 학습
from keras.layers import BatchNormalization
def mlp_model():
model = Sequential()
model.add(Dense(50, input_shape = (784, )))
model.add(BatchNormalization()) # Add Batchnorm layer before Activation
model.add(Activation('sigmoid'))
model.add(Dense(50))
model.add(BatchNormalization()) # Add Batchnorm layer before Activation
model.add(Activation('sigmoid'))
model.add(Dense(50))
model.add(BatchNormalization()) # Add Batchnorm layer before Activation
model.add(Activation('sigmoid'))
model.add(Dense(50))
model.add(BatchNormalization()) # Add Batchnorm layer before Activation
model.add(Activation('sigmoid'))
model.add(Dense(10))
model.add(Activation('softmax'))
sgd = optimizers.SGD(lr = 0.001)
model.compile(optimizer = sgd, loss = 'categorical_crossentropy', metrics = ['accuracy'])
return model
model = mlp_model()
history = model.fit(X_train, y_train, validation_split = 0.3, epochs = 100, verbose = 0)
모델 학습 결과 시각화
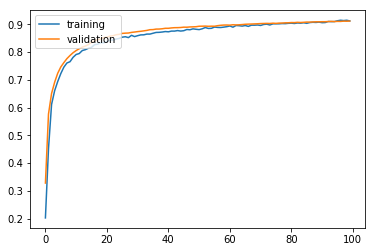
모델 평가
기본 모델에 배치정규화만 적용했음에도 불구하고 91.54%의 높은 정확도를 보인다. 앞으로 네트워크를 만들 때 배치 정규화는 웬만하면 적용해 주는 것이 좋다(논문에 따르면 뒤에서 나올 regularization의 효과도 있어 배치 정규화를 적용하면 드랍아웃을 적용하지 않아도 된다고 한다).
results = model.evaluate(X_test, y_test)
print('Test accuracy: ', results[1])
Test accuracy: 0.9154
드랍아웃(Dropout)
드랍아웃은 앞서 배치 정규화에서 잠깐 언급했던 regularization의 효과를 위한 방법이다. 아이디어 자체는 굉장히 단순하다. 어떤 레이어에 드랍아웃을 적용하면, 그 레이어의 모든 노드에서 나가는 activation을 특정 확률로 지워버린다.
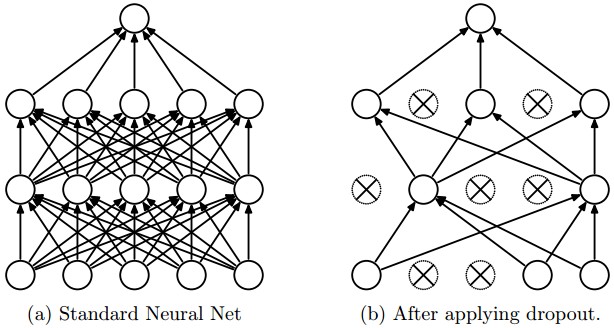
이렇게 간단한 아이디어가 왜 필요하냐고 물어볼 수 있겠지만, 그 이유는 역설적이게도 뉴럴 네트워크가 너무 똑똑해지는(기억력이 좋아지는) 것을 방지하는 것이다. 예를 들어, 토익 시험을 본다고 생각을 하자. 연습 문제를 가지고 공부를 하는데 연습 문제의 리스닝 셋에서 강아지 사진이 있는 문제의 답이 모두 C라고 가정하자. 어떤 학생이 연습 문제를 가지고 너무 공부를 열심히 한 나머지 강아지 사진이 있는 문제의 답은 C라고 외워버리게 되고, 실전에서 강아지 문제가 나오자 마자 답을 C로 찍어버렸는데 사실 그 문제의 답은 D였던 것이다. 제 3자가 보면 말도 안되는 이야기지만 학생 입장에서는 공부를 정말 열심히해서 연습 문제의 답까지 외워버렸는데 막상 실전에 가서 문제를 틀려버린 상황이 된 것이다.
이것이 바로 학습 데이터에 대한 “과적합(overfitting)” 문제이며, 드랍아웃은 이러한 상황을 방지하기 위한 장치이다. 일부러 모델을 학습할 때 일부 노드의 activation을 지워버려 다소 “멍청한(기억력이 떨어지는)” 모델을 만들어 문제에 대한 과적합(overfitting)을 막는다. 물론 검증할 때에는 모든 activation을 다시 살린다(실전에 가서는 모든 기억력을 총동원하는 것처럼…).
우리 예에서는 드랍아웃이 의미가 없을 수 있겠으나, ResNet과 같이 복잡하고 거대한 모델을 만들 때 드랍아웃은 유의미한 성능을 발휘한다. 모델이 “딥(deep)”해지면 해질수록 데이터에 대한 학습 과적합이 일어나기 십상이기 때문에, 이러한 경우 드랍아웃을 통해 과적합을 줄이고 검증 정확도를 높일 수 있다.
모델을 만들었는데 학습 정확도가 검증 정확도에 비해 지나치게 높으면 늘 과적합을 의심하고 드랍아웃을(혹은 유사한 효과를 갖는다고 하는 배치 정규화를) 적용해 보자.
케라스에서 드랍아웃을 적용할 때에는 일반적으로 활성 함수(Activation) 레이어 뒤에 붙이며, 인자로 activation을 드랍할 확률인 dropout_rate를 설정해 주어야 한다.
모델 생성 및 학습
from keras.layers import Dropout
def mlp_model():
model = Sequential()
model.add(Dense(50, input_shape = (784, )))
model.add(Activation('sigmoid'))
model.add(Dropout(0.2))
model.add(Dense(50))
model.add(Activation('sigmoid'))
model.add(Dropout(0.2))
model.add(Dense(50))
model.add(Activation('sigmoid'))
model.add(Dropout(0.2))
model.add(Dense(50))
model.add(Activation('sigmoid'))
model.add(Dropout(0.2))
model.add(Dense(10))
model.add(Activation('softmax'))
sgd = optimizers.SGD(lr = 0.001)
model.compile(optimizer = sgd, loss = 'categorical_crossentropy', metrics = ['accuracy'])
return model
model = mlp_model()
history = model.fit(X_train, y_train, validation_split = 0.3, epochs = 100, verbose = 0)
모델 학습 결과 시각화
앞서 말했다시피, 우리 모델은 복잡한 모델이 아니기 때문에 과적합이 일어나지 않았고, 드랍아웃이 이 상황에서는 의미가 없다. 오히려 정확도를 감소시킨다.
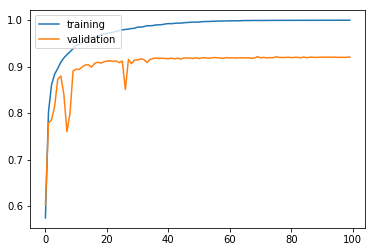
모델 평가
기본 모델에 비해 test accuracy가 낮아졌다. 원래 학습 데이터를 가지고 공부를 제대로 하지 않은 애한테 공부한 시간을 빼앗은 꼴이다..
results = model.evaluate(X_test, y_test)
print('Test accuracy: ', results[1])
Test accuracy: 0.1135
앙상블(Model Ensemble)
모델 앙상블 또한 매우 강력한 개념이다. CS231n 강좌에 따르면, 모델 앙상블을 적절하게 하면 웬만하면 정확도가 1~2% 정도는 올라간다고 한다. 원래 머신러닝에서 앙상블하는 것도 bootstrapping, bagging 등 여러 가지 방법이 있는 것처럼 뉴럴 네트워크의 앙상블도 여러 가지 방법이 있다. 자세한건 여기를 참조하자.
앙상블이 효과를 발휘하는 이유를 간단히 설명하자면, 네트워크를 학습할 때 마다 가중치 초기값이 조금씩 달라 결과가 조금씩 달라진다. 이에 따라 어느 정도의 randomness를 가지고 모델마다 결과가 미묘하게 달라진다(차이의 크기는 데이터, 네트워크 마다 다름). 앙상블은 이처럼 서로 다른 모델들을 합쳐 일종의 “집단지성(collective intelligence)”을 발휘하여 각기 하나의 모델보다 나은 최종 모델을 만들어 낸다. 요약하자면 “백지장도 맞들면 낫다” 정도.
앙상블을 할 때에는 일반적으로 멍청한 모델(underfitting)이 똑똑한 모델(overfitting)보다 낫고, 모델 간의 차이가 크면 클수록 좋다. 물론 일반론이므로 결과는 항상 돌려봐야만 확인할 수 있다. (CS231n에서 배운 것과는 다르게 앙상블 했는데 정확도 개선이 전혀 없는경우도 있다…)
모델 생성 및 학습
scikit-learn에 있는 VotingClassifier를 적용해보자. 서로 다른 모델을 합쳐서 결과값을 다수결로 결정한다(voting).
import numpy as np
from keras.wrappers.scikit_learn import KerasClassifier
from sklearn.ensemble import VotingClassifier
from sklearn.metrics import accuracy_score
def mlp_model():
model = Sequential()
model.add(Dense(50, input_shape = (784, )))
model.add(Activation('sigmoid'))
model.add(Dense(50))
model.add(Activation('sigmoid'))
model.add(Dense(50))
model.add(Activation('sigmoid'))
model.add(Dense(50))
model.add(Activation('sigmoid'))
model.add(Dense(10))
model.add(Activation('softmax'))
sgd = optimizers.SGD(lr = 0.001)
model.compile(optimizer = sgd, loss = 'categorical_crossentropy', metrics = ['accuracy'])
return model
# 서로 다른 모델을 3개 만들어 합친다
model1 = KerasClassifier(build_fn = mlp_model, epochs = 100, verbose = 0)
model2 = KerasClassifier(build_fn = mlp_model, epochs = 100, verbose = 0)
model3 = KerasClassifier(build_fn = mlp_model, epochs = 100, verbose = 0)
ensemble_clf = VotingClassifier(estimators = [('model1', model1), ('model2', model2), ('model3', model3)], voting = 'soft')
ensemble_clf.fit(X_train, y_train)
y_pred = ensemble_clf.predict(X_test)
모델 평가
다행히도(?) 우리 모델에서는 3개 합치자 정확도가 조금 올라갔다.
print('Test accuracy:', accuracy_score(y_pred, y_test))
Test accuracy: 0.3045
이번 포스팅에서는 뉴럴 네트워크의 학습 과정을 개선시킬 수 있는 나머지 세 가지 방식에 대해 알아봤다. 뉴럴 네트워크와 관련하여 연구가 계속 지속되고 있는 만큼, 이 외에도 모델을 개선할 수 있는 방법이 수많이 존재하고 모델마다 적합한 방식이 다르다. 이처럼 실험해야 될 경우의 수가 많아질수록 케라스와 같은 high-level API가 강점을 발휘하는 것이 아닐까 싶다. 코드를 모듈화하고 파라미터를 조금씩만 바꾸어가면서 여러 가지 테스팅을 최대한 많이 해보는 것이 현실에서 데이터 마이닝 문제를 풀 때 가장 좋은 접근법이라고 생각한다.
전체 코드
본 실습의 전체 코드는 여기에서 열람하실 수 있습니다!