
케라스와 함께하는 쉬운 딥러닝 (14) - 다양한 CNN 구조
23 Jun 2019 | Python Keras Deep Learning 케라스합성곱 신경망 8 - 다양한 CNN 구조
Objective: 케라스로 다양한 CNN 모델을 만들어 본다.
지난 포스팅에서 케라스로 문장 분류를 위한 2-D CNN 모형을 IMDB MOVIE REVIEW SENTIMENT 데이터를 활용하여 만들어 보았으며, 간단한 1-D CONVOLUTION (TEMPORAL CONVOLUTION)보다 개량된 정확도인 86.6%의 test accuracy를 기록하였다.
이번 포스팅에는 문장 분류를 위한 CNN의 학습 과정을 개선시키고 안정화할 수 있는 여러 가지 방법을 탐구해 보자.
IMDB 데이터 셋 불러오기
IMDB 영화 리뷰 감성분류 데이터 셋(IMDB Movie Revies Sentiment Classification Dataset)은 총 50,000 개의 긍정/혹은 부정으로 레이블링된 데이터 인스턴스(즉, 50,000개의 영화 리뷰)로 이루어져 있으며, 케라스 패키지 내에 processing이 다 끝난 형태로 포함되어 있다.
리뷰 데이터를 불러올 때 주요 파라미터는 아래와 같다
num_features: 빈도 순으로 상위 몇 개의 단어를 포함시킬 것인가를 결정sequence_length: 각 문장의 최대 길이(특정 문장이sequence_length보다 길면 자르고,sequence_length보다 짧으면 빈 부분을 0으로 채운다)를 결정embedding_dimension: 각 단어를 표현하는 벡터 공간의 크기(즉, 각 단어의 vector representation의 dimensionality)
import numpy as np
import matplotlib.pyplot as plt
from keras.datasets import imdb
from keras.preprocessing.sequence import pad_sequences
num_features = 3000
sequence_length = 300
embedding_dimension = 100
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words = num_features)
X_train = pad_sequences(X_train, maxlen = sequence_length)
X_test = pad_sequences(X_test, maxlen = sequence_length)
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
(25000, 300), (25000, 300), (25000,), (25000,)
2-D CNN WITH DIFFERENT SETTINGS
지난번 포스팅의 마지막 모델과 비슷한 구조를 갖고 있지만 Dropout과 Batch Normalization 등 MLP모델을 안정화시키는 데 활용한 기법들을 CNN 구조에도 동일하게 활용해 본다.

자신이 만든 CNN 모델이 제대로 작동하지 않고 지나치게 낮은 training/test accuracy를 보인다면, 이러한 기법들을 조합하여 성능을 높일 수도 있다.
from keras.models import Model
from keras.layers import concatenate, Input
filter_sizes = [3, 4, 5]
# 합성곱 연산을 적용하는 함수를 따로 생성. 이렇게 만들어 놓으면 convolution 레이어가 여러개더라도 편리하게 적용할 수 있다.
def convolution()
inn = Input(shape = (sequence_length, embedding_dimension, 1))
convolutions = []
# we conduct three convolutions & poolings then concatenate them.
for fs in filter_sizes:
conv = Conv2D(filters = 100, kernel_size = (fs, embedding_dimension), strides = 1, padding = "valid")(inn)
nonlinearity = Activation('relu')(conv)
maxpool = MaxPooling2D(pool_size = (sequence_length - fs + 1, 1), padding = "valid")(nonlinearity)
convolutions.append(maxpool)
outt = concatenate(convolutions)
model = Model(inputs = inn, outputs = outt)
return model
# 여러가지 기법이 추가된 2D CNN 모델을 만들고 학습시키기 위한 함수
def imdb_cnn_4():
model = Sequential()
model.add(Embedding(input_dim = 3000, output_dim = embedding_dimension, input_length = sequence_length))
model.add(Reshape((sequence_length, embedding_dimension, 1), input_shape = (sequence_length, embedding_dimension)))
model.add(Dropout(0.5))
# call convolution method defined above
model.add(convolution())
model.add(Flatten())
model.add(Dense(10))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(10))
model.add(Activation('relu'))
model.add(BatchNormalization())
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid'))
adam = optimizers.Adam(lr = 0.001)
model.compile(loss='binary_crossentropy', optimizer=adam , metrics=['accuracy'])
return model
model = imdb_cnn_4()
모델을 학습시키고 검증해 보자
history = model.fit(X_train, y_train, batch_size = 50, epochs = 100, validation_split = 0.2, verbose = 0)
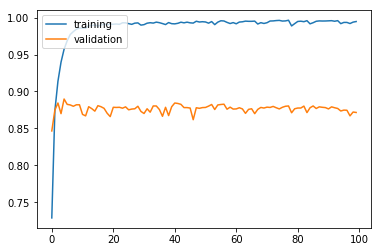
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.legend(['training', 'validation'], loc = 'upper left')
plt.show()
results = model.evaluate(X_test, y_test)
print('Test accuracy: ', results[1])
검증 정확도 86.8%로 지난번 모델과 비슷한 정확도를 보이지만 성능을 높이기 위해 여러 기법들을 활용할 수 있다는 점을 유의하자. 지금도 딥 러닝 모델의 학습을 위한 새로운 기법들이 꾸준히 제안되고 있다.
Test accuracy: 0.86876
전체 코드
본 실습의 전체 코드는 여기에서 열람하실 수 있습니다!