
Attention in Neural Networks - 3. Sequence-to-Sequence (Seq2Seq) (2)
12 Jan 2020 | Attention mechanism Deep learning PytorchAttention Mechanism in Neural Networks - 3. Sequence-to-Sequence (Seq2Seq) (2)
In the previous posting, we had a first look into Sequence-to-Sequence (Seq2Seq). In this posting, prior to implementing Seq2Seq models with Python, let’s see how to prepare data for neural machine translation.
Problem - neural machine translation
The task of machine translation is to automate the process of converting sentences in one language (e.g., French) to ones in another language (e.g., English). The sentences (words) that we want to convert are often called source sentences (words). And sentences (words) that are converted into are target sentences (words). In the diagram below demonstrating translation from French to English, the first source words are “On”, “y” and “va,” while target words are “Let’s” and “go.”
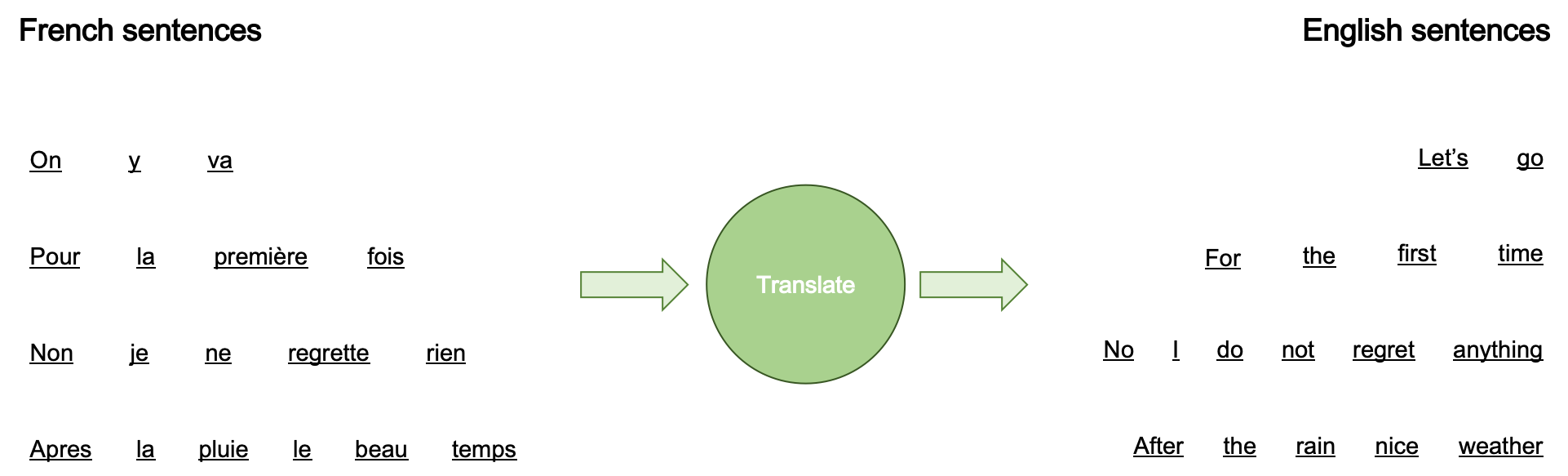
Neural machine translation is a branch of machine translation that actively utilizes neural networks, such as recurrent neural networks and multilayer perceptrons, to predict the likelihood of a possible word sequence in the corpus. So far, neural machine translation has more succesfully tackled problems in machine translation that have outlined in the previous posting.
Many of earlier ground-breaking studies in neural machine translation employ Seq2Seq architecture, e.g., Cho et al. (2014). In this posting, let’s look into how to prepare data for neural machine translation with Python. I will use Google Colaboratory for this attention posting series, so if you are new to it, please check out my posting on Colaboratory.
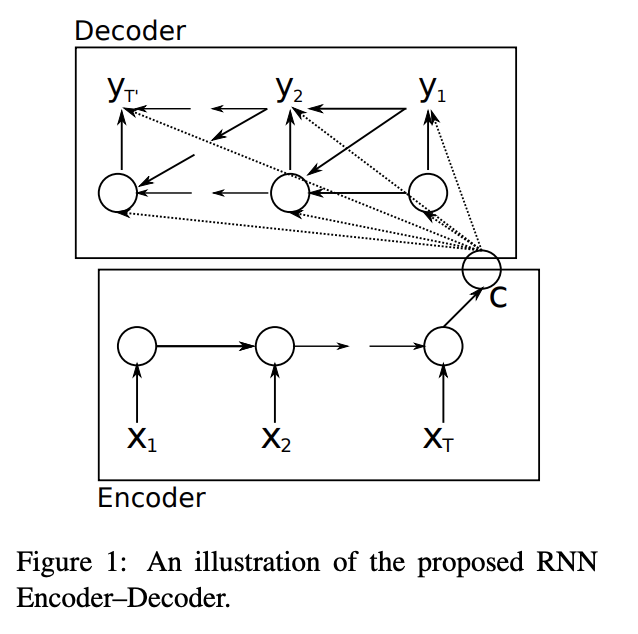 [Image source: Cho et al. (2014)]
[Image source: Cho et al. (2014)]
Dataset
The dataset used in this posting is English-German sentence pairs dataset downloaded from here. They provide not only German sentences corresponding to English ones, but also other languages such as French, Arabic, and Chinese. So if you want to try out translating other languages, please check out the website!
The data are tab-separated, with each line consisting of English sentence + TAB + Another language sentence + TAB + Attribution. Therefore, we can extract (English sentence, another language sentence) from each line while splitting each line with TAB (“\t”).

Let’s start out with importing necessary packages. We do not need many packages for this practice and they are already installed in the Colab environment. We just need to import them.
import re
import torch
import numpy as np
import torch.nn as nn
from tqdm import tqdm
Download & Read data
Let’s download and unzip the dataset first. You can also manually download and unzip them in your machine, but you can just run below Linux command in your colaboratory file.
!wget https://www.manythings.org/anki/deu-eng.zip
!unzip deu-eng.zip
You will get below output if the file is successfully downloaded and unzipped.
-2020-01-13 09:30:06-- https://www.manythings.org/anki/deu-eng.zip
Resolving www.manythings.org (www.manythings.org)... 104.24.108.196, 104.24.109.196, 2606:4700:30::6818:6dc4, ...
Connecting to www.manythings.org (www.manythings.org)|104.24.108.196|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 7747747 (7.4M) [application/zip]
Saving to: ‘deu-eng.zip’
deu-eng.zip 100%[===================>] 7.39M 7.53MB/s in 1.0s
2020-01-13 09:30:13 (7.53 MB/s) - ‘deu-eng.zip’ saved [7747747/7747747]
Archive: deu-eng.zip
inflating: deu.txt
inflating: _about.txt
After the file is downloaded, we can open the file and read them. I prefer to read txt files with the readlines() function, but you can also try it with the read() function.
with open("deu.txt") as f:
sentences = f.readlines()
# number of sentences
len(sentences)
The length of the list storing data is 200,519. In other words, there are 200,519 English-German sentence pairs in total.
200519
Preprocessing
Every dataset needs preprocessing, especially it is unstructured data like text. For the sake of minimizing time and computational costs involved, we will randomly choose 50,000 pairs for training the model. Then, we will leave only alphabetic characters and tokenize the sentence. Also, letters will be changed into lowercase letters and unique tokens will be extracted in separate sets. In addition, we add “start of the sentence” ("<sos>") and “end of the sentence” (<eos>) tokens to the start and end of the sentences. This will let the machine detect the head and tail of each sentence.
NUM_INSTANCES = 50000
eng_sentences, deu_sentences = [], []
eng_words, deu_words = set(), set()
for i in tqdm(range(NUM_INSTANCES)):
rand_idx = np.random.randint(len(sentences))
# find only letters in sentences
eng_sent, deu_sent = ["<sos>"], ["<sos>"]
eng_sent += re.findall(r"\w+", sentences[rand_idx].split("\t")[0])
deu_sent += re.findall(r"\w+", sentences[rand_idx].split("\t")[1])
# change to lowercase
eng_sent = [x.lower() for x in eng_sent]
deu_sent = [x.lower() for x in deu_sent]
eng_sent.append("<eos>")
deu_sent.append("<eos>")
# add parsed sentences
eng_sentences.append(eng_sent)
deu_sentences.append(deu_sent)
# update unique words
eng_words.update(eng_sent)
deu_words.update(deu_sent)
So, now we have 50,000 randomly selected English and German sentences that are paired with corresponding indices. To get the indices for the tokens, let’s convert the unique token sets into lists. Then, for the sanity check, let’s print out the sizes of the English and German vocabulary in the corpus.
eng_words, deu_words = list(eng_words), list(deu_words)
# print the size of the vocabulary
print(len(eng_words), len(deu_words))
There are 9,209 unqiue English tokens and 16,548 German tokens. It is interesting to see there are about two times more tokens in German than in English.
9209 16548
Finally, let’s convert words in each sentence into indices. This will make the information more accessible and understandable for the machine. Such indexed sentences will be inputs for the implemented neural network models.
# encode each token into index
for i in tqdm(range(len(eng_sentences))):
eng_sentences[i] = [eng_words.index(x) for x in eng_sentences[i]]
deu_sentences[i] = [deu_words.index(x) for x in deu_sentences[i]]
Now, we are done with importing and preprocessing English-German data. For the final sanity check, let’s try printing out the encoded and raw sentences. Note that the selected sentences can be different on your side since we randomly select 50,000 sentences from the corpus.
print(eng_sentences[0])
print([eng_words[x] for x in eng_sentences[0]])
print(deu_sentences[0])
print([deu_words[x] for x in deu_sentences[0]])
[4977, 8052, 5797, 8153, 5204, 2964, 6781, 7426]
['<sos>', 'so', 'far', 'everything', 'is', 'all', 'right', '<eos>']
[9231, 8867, 7020, 936, 13206, 5959, 13526]
['<sos>', 'soweit', 'ist', 'alles', 'in', 'ordnung', '<eos>']
In this posting, Seq2Seq and its overall architecture have been introduced. In the next posting, I will implement the Seq2Seq model with Pytorch and show how to train it with the preprocessed data. Thank you for reading.