This is a short talk by Swami Sarvapriyananda on how to concentrate. Before starting this posting, I want to emphasize that this is not a religious or spiritual talk, though some ideas from yoga and Swami Vivekananda’s philosophy are mentioned. Swami Sarvapriyananda provides very practical methods to maximize concentration and focus with his profound knowledge in science, philosophy, and yoga. Personally, I have been quite interested in concentration and also intensely practicing Raja yoga and Zen during the COVID-19 pandemic and greatly improved my focus (and my life overall). In my opinion, this lecture can be a great starting point for someone who wants to improve their ability to focus (and life).
Secret in success
“Every problem could be solved if one could concentrate hard enough” - Von Neumann
This quote by Von Neumann, a great mathematician/physicist, that Swami Sarvapriyananda accidentally encountered is reminiscent of Swami Vivekananda’s idea. According to Swami Vivekananda, the secret to all knowledge lies in concentration. The difference between an ordinary person and a great person lies in the degree of concentration. Interestingly, Warren Buffet and Bill Gates, two of the brightest and richest people in the last century, picked “focus” as the single most factor in their succcess through life.
Impediments to concentration - modern technology
 [Image source]
[Image source]
In short, modern information technologies, such as social media and mobile devices, are very detrimental to concentration. As competition gets fiercer and fiercer in the digital space, many IT companies are increasingly offering their products gratuitously. We can use many web and mobile applications without charge, such as Google search, YouTube, Facebook, Instagram, and Whatsapp, to name just a few. However, instead of charging users explicitly, they are striving to grab their attention. And the user’s engagement while using the service is a new type of currency in the attention economy of the 21st century. As users use an application more frequently and subconciously, the company creates monetary value from them by advertising, subsidy, freemium services, etc. If you want to know more on how IT companies make money in free economy, refer to literature on two-sided markets and attention economy.
From the user’s perspective, companies enticing users to use their applications without any charge might look like a dream world. We can now use a large number of enormously sophsticated applications for free, ranging from social media, news, messengers, and so on. However, as always, there is no free lunch. As companies are trying hard to grab users’ attention, we are somehow becoming addicted to little dopamine rushes everyday. A new notification with a “ting” on your phone, e.g., a new message in Whatsapp, a new video uploaded by your favorite YouTuber, and a new photo update of your best friend on Instagram, gives you tiny pleasure in anticipation of something new and interesting. Thousands of brilliant people with knowledge in technology and human psychology work day and night to keep you engaged and loyal to the application. This makes you divert from work that you are doing and invest some mental effort in reacting to the notification. And this happens more often as we get addicted to the dopamine rush. The fact that this is a very subtle and relatively less damaging addiction makes it difficult to regulate and prevent from happening.
This has become a quite serious issue. When I observe people nowadays, many get very anxious when they cannot check their phones or laptops periodically. A few years ago, I used to note such patterns among young people, but recently, I recognize more and more older people than me becoming addicted to mobile services and lose their focus periodically. So it’s becoming a universal problem to people with access to developed IT. To be honest, I sometimes become very sticky to such apps - I find myself binge-watching YouTube videos or unconsciously checking the Facebook newsfeed.
Then how can we regain our ability to focus? Swami Sarvapriyananda gives some hints in this talk based on science of focus and Swami Vivekananda’s education philosophy. Below are some of the key points of the lecture, with my comments.
The Science of FLOW
According to Mihaly Csikszentmihalyi, the author of Flow: The Psychology of Optimal Experience, our cognitive bandwith is quite limited. Specifically, we can process about 110 bits of information every second. For example, it is difficult to talk to two people at the same time separately. Then, Csikszentmihalyi argues that concentration is how much cognitive bandwith can we take and limit our attention on one subject at a time. Thus, if we can deeply focus on one thing, there is little mental capacity to attend to other external things.
Balance challenge and skills
An important technique to enhance the ability to concentrate is to balance between the difficulty of a task and your capability. If the task is too challenging or demanding, it is likely to make you anxious and worried. In contrast, if your skill exceeds the difficulty by a great margin, you are likely to be bored easily. Hence, to maximize your attention, you should carefully choose the appropriate task after examining your own capability. And such state of maximum concentration is called flow.
Concentration is an enjoyable experience
Flow is not only productive and engaging, but also pleasurable. After you deeply focus on something, you tend to feel very satisfying, happy, fulfilled, and integrated. In contrast, after wasting hours surfing internet or binge watching Netflix, you are likely to feel lethargic and disoriented. Furthermore, how much you can concentrate on one thing is related to overall happiness and satisfaction in life. If you can divert yourself from unnecessary worries and concerns and focus on important things in life, you can be more successful and happy in the long run.
Practice makes perfect
Persistence is the key in concentration as well. Many people think mental capabilities are something that we can easily acquire or cannot be developed after birth. However, like when training your muscles, consistently working hard to develop the ability to focus is of great importance. In my experience, this creates a positive loop in your life. As one develops the ability to focus, things are done much impeccably. Then, one is further motivated to develop the ability and performances improve much more, and so on. This is why some people like Gates and Buffet succeeds enormously, even though they don’t look extraordinarily different from other people.
Raja yoga - the best method for concentration.
 [Image source]
[Image source]
There is a snake surrounding the emblem of Ramakrishna order, which was designed by Swami Vivekananda himself. The serpent implies (raja) yoga and awakened kundalini. When a snake is approaching a prey, it is intensely focusing. Also, it is extending its hood, which can be interpreted as cutting out all distractions. Finally, it holds onto one thing for a long period of time. To summarize, three key aspects of concentration are (1) focusing on one thing, (2) removing all other things that can be distractions, and (3) keeping the attention for as long as possible.
Hence, if you want to maximize your flow while working on something, you would better get rid of everthing that can potentially distract you. Nowadays, information technologies that we discussed such as mobile phones and social media should be avoided at all costs when you are focusing.
According to Csikszentmihalyi, the best guide to improve focus is Yoga sutras of Patajali. And Daniel Goleman also dedicates pages describing the science behind meditation. I won’t go into the details of Yoga and meditation here since you can find them easily online nowadays. But, I can assure you that they really work.
Be a single-tasker
This is actually quite opposite to what we usually do nowadays. People are so used to multi-tasking - while working, they listen to music, consistently check emails and messages, think about what to do after work, and so on. And it might be productive in the short run, since time is limited. However, in the long run, it is desirable to focus on one thing at a time to develop your focus and maintain productivity in the long run. One practical suggestion given by Swami is to intensely focus on one thing for a short span of time and take rest after that. Also, even when you are doing relatively petty things such as chatting with a friend or watching a movie on Netflix, focus on just that thing that you are doing.
Towards unselfishness
Swami Vivekananda emphasized unselfishness over concentration. The ability to concentrate is a great psychic power. And we have seen throughout the history that if that power is misused, there can be catastrophic consequences. It is important to balance self-centeredness and unselfishness when applying your focus in daily work you perform.
Resources
- The Social Dilemma
- Mihaly Csikszentmihalyi, Flow: The Psychology of Optimal Experience
- Daniel Goleman, Focus: The Hidden Driver of Excellence

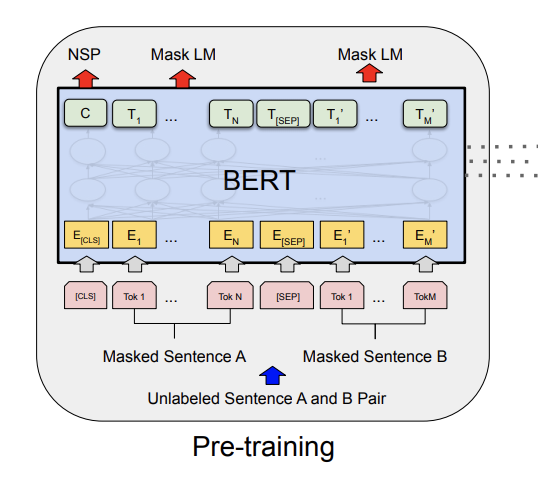 [Devlin et al. 2019]
[Devlin et al. 2019]
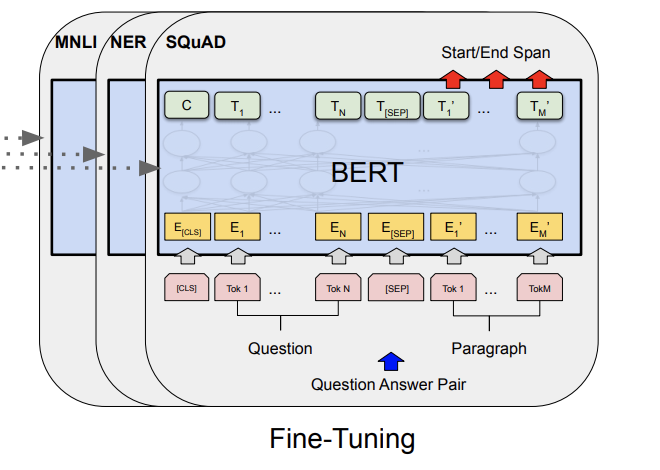 [Devlin et al. 2019]
[Devlin et al. 2019]

![[Image source]](https://occ-0-1068-92.1.nflxso.net/dnm/api/v6/X194eJsgWBDE2aQbaNdmCXGUP-Y/AAAABSbpqs6JAOMic369rooO6Q7bqPSDclenFVfHkGK1LPHycRPPxDRL3xNKteLy1TAcWK8HfTQS0OYtcHJlf-lXtaxT5gvfr53NsF2lEuXf7rT4bTyRqqO5lSPcL7h_JA.jpg?r=9dd){kind=link}