
Implementing Matrix Factorization models in Python - Collaborative filtering with Python 14
22 Oct 2020 | Python Recommender systems Collaborative filteringSo far, we have studied the overall matrix factorization (MF) method for collaborative filtering and two popular models in MF, i.e., SVD and SVD++. I believe now we know how MF models are designed and trained to learn correlation patterns between user feedback behaviors. In this posting, without further ado, let’s try implementing MF in Python using Surprise.
Data preparation
Let’s load the MovieLens dataset, which was used in prior postings. For more information on importing and loading the built-in dataset, please refer to the previous posting
from surprise import Dataset
dataset = Dataset.load_builtin()
Implementing SVD
Training and evaluating SVD is very straightforward, similar to implementing the k-NN and baseline estimator when using Surprise. We just need to define the model with SVD() - Surprise will take care of most of the things for us. Again, let’s try five-fold cross-validating.
from surprise import SVD
clf = SVD()
cross_validate(clf, dataset, measures=['MAE'], cv=5, verbose=True)
To our dismay, SVD does not seem to do extremely well in this case. In fact, it shows test MAE scores slightly above 0.73. This is on a par with k-NN with the baseline estimator that we have implemented in this posting.
Evaluating MAE of algorithm SVD on 5 split(s).
Fold 1 Fold 2 Fold 3 Fold 4 Fold 5 Mean Std
MAE (testset) 0.7398 0.7365 0.7410 0.7353 0.7378 0.7381 0.0021
Fit time 4.99 5.03 5.00 5.03 4.99 5.01 0.02
Test time 0.14 0.22 0.14 0.22 0.14 0.17 0.04
{'fit_time': (4.988102436065674,
5.031152009963989,
4.997517824172974,
5.02509069442749,
4.992721796035767),
'test_mae': array([0.7398014 , 0.73648218, 0.74099867, 0.73526241, 0.73778967]),
'test_time': (0.14092421531677246,
0.2161257266998291,
0.13858461380004883,
0.21789216995239258,
0.1449432373046875)}
But again, don’t be discouraged too early. Remember the first k-NN model that we implemented actually performed worse than the baseline estimator? There might be some things that we could do here as well.
Parameter tuning with grid search
Remember the accuracy scores fluctuated as we changed $k$ when implementing k-NN models? We also learned that $k$ is a hyperparameter that should be determined prior to training a machine learning model. We can do a similar thing here, but with different hyperparameters.
From my experience, two of the most important hyperparameters when running the stochastic gradient descent (SGD) algorithm are learning rate and number of epochs. Learning rate is the value $\gamma$ that is used to update the parameters and number of epochs counts how many parameter updates that the model is to carry out. The default settings for learning rate and number of epochs are 0.005 and 20, respectively. However, this might not be the optimal setting for our data.
Hence, let’s try grid search, which is an optimization scheme trying all possible combinations of specified hyperparameter choices. For more information on hyperparameter optimization, please refer to this Wikipedia article. Below code runs grid search using five-fold cross validation and prints out the best MAE and hyperparameter combinations that yielded the best score. Specifically, we try 16 (4 by 4) possible combinations of two parameters:
- learning rate: (5, 10, 20, 30)
- number of epochs: (.0025, .005, .001, .01)
from surprise.model_selection import GridSearchCV
grid = {'n_epochs': [5, 10, 20, 30],
'lr_all': [.0025, .005, .001, .01]}
gs = GridSearchCV(SVD, grid, measures=['MAE'], cv=5)
gs.fit(dataset)
print(gs.best_score['mae'])
print(gs.best_params['mae'])
However, again to our dismay, the result has not improve significantly - it shows MAE of around 0.73.
0.7374588888101046
{'n_epochs': 10, 'lr_all': 0.01}
SVD++
Even after tuning parameters, SVD didnt’s show superior performance to other models. Now, let’s try out SVD++, which is known to improve SVD. Fortunately, implementing SVD++ is very convenient - just replace SVD() with SVDpp().
from surprise import SVDpp
clf = SVDpp()
cross_validate(clf, dataset, measures=['MAE'], cv=5, verbose=False)
Finally, we are able to get results that are better than baselines. SVDpp shows test MAE around 0.72, which is slightly lower than scores from k-NN and SVD.
{'fit_time': (163.75455975532532,
163.009015083313,
163.31932163238525,
163.62001395225525,
163.37179136276245),
'test_mae': array([0.72057974, 0.71956503, 0.72017268, 0.71820603, 0.72156721]),
'test_time': (4.107621908187866,
3.976837635040283,
3.9505584239959717,
3.752680778503418,
3.8454060554504395)}
Additional considerations…
Although SVD++ shows better performance to other models that we have seen so far, it is not always desirable to use SVD++. If you have run the code in this posting, you would have noticed that SVD++ takes considerably longer time to train, compared to the naive SVD. Also, MF models, which are more complex than k-NN or baseline models, require more hyperparameters to tune for optimal performance. Finally, there is the problem of interpretability (or explainability or transparency), which is a critical issue for practical usage. It is often risky to blindly deploy the most accurate model without assessing its inner workings. Moreover, in general, more accurate models tend to be less interpretable, i.e., interpretability-accuracy tradeoff.
For such reasons, I oftentimes use very simple and light models for practical applications such as logistic regression and rule-based methods. And the recommender systems field is not an exception - it might be better to use simple memory-based models than fancy models such as SVD++ or neural net-based models, although the latter shows superior test accuracy. Unfortunately, there is no clear-cut answer to this - you should try as many approaches as possible and come up with an optimal solution that satisfies problem contraints, e.g., available computing resources and the need for interpretations.
References
- Koren, Y., Bell, R., & Volinsky, C. (2009). Matrix factorization techniques for recommender systems. Computer, 42(8), 30-37.
- Ricci, F., Rokach, L., & Shapira, B. (2011). Introduction to recommender systems handbook. In Recommender systems handbook (pp. 1-35). Springer, Boston, MA.
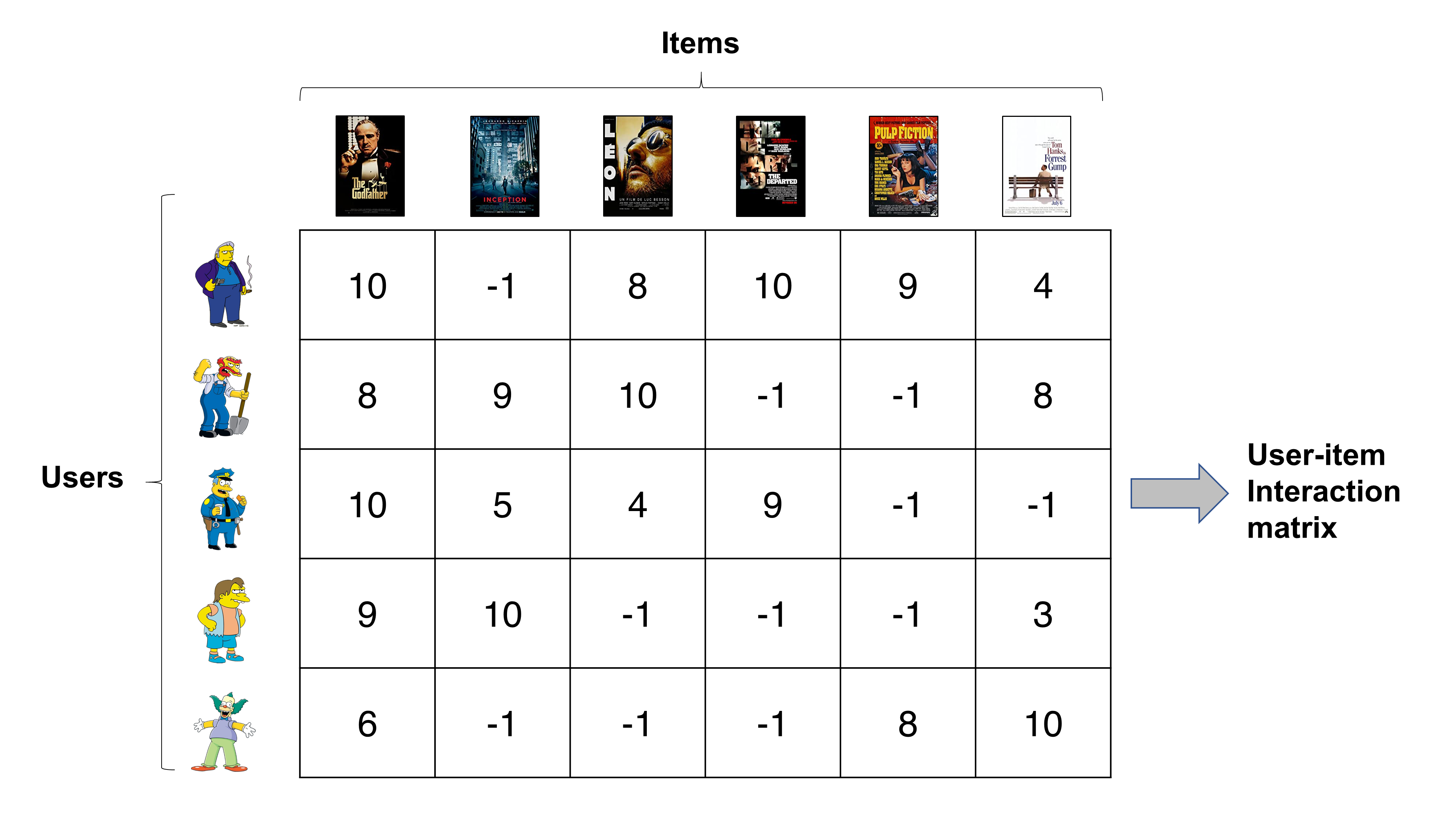
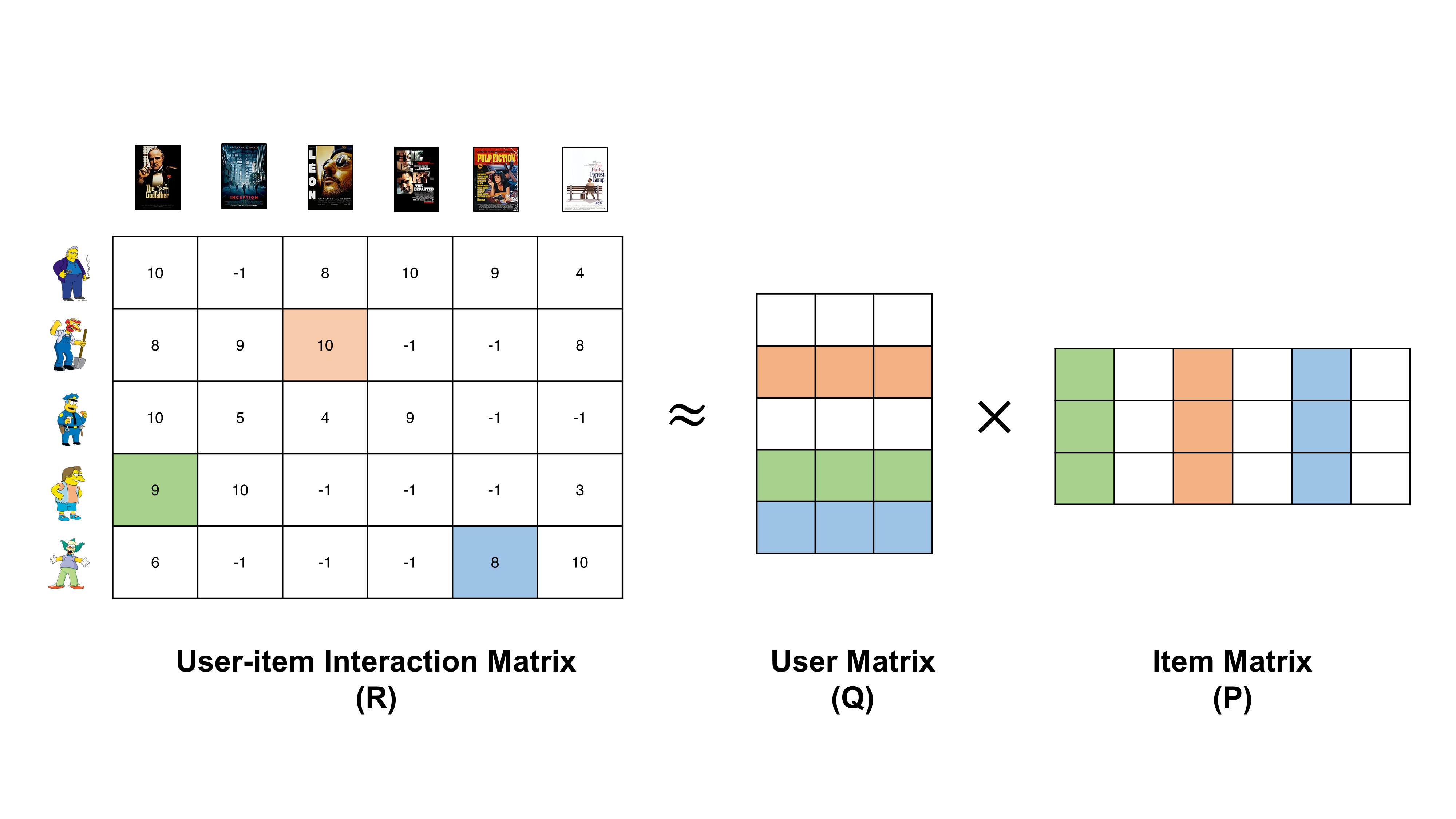

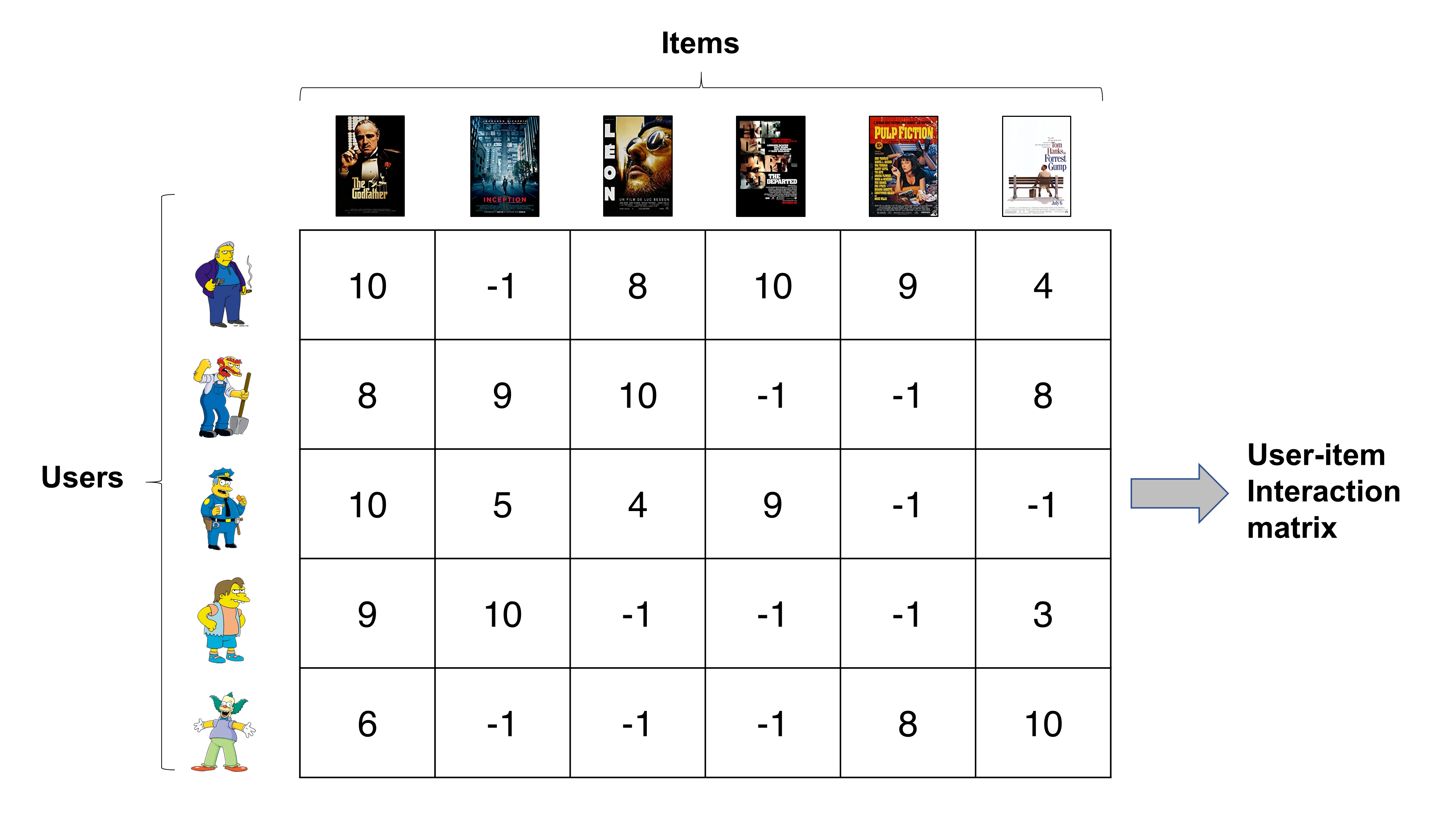
 [Image source: Töscher et al. 2009]
[Image source: Töscher et al. 2009]
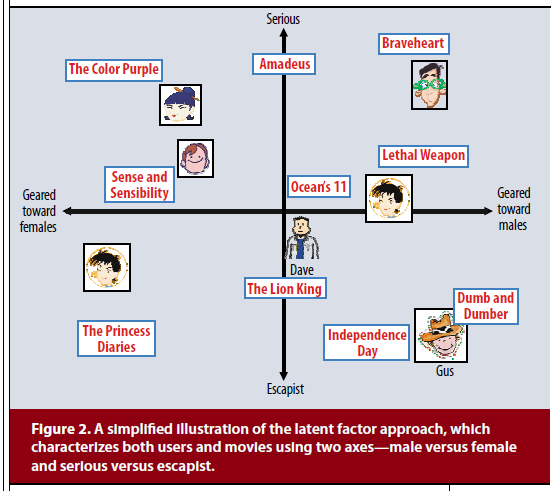 [Image source: Koren et al. 2009]
[Image source: Koren et al. 2009]

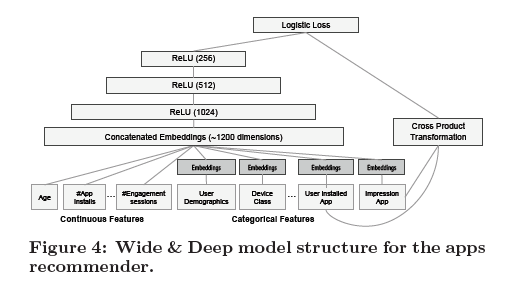 [Image source: Cheng et al. (2016)]
[Image source: Cheng et al. (2016)]
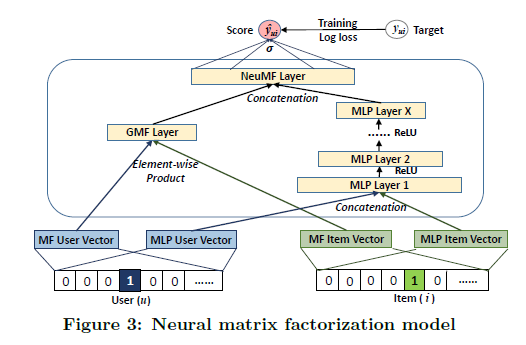 [Image source: He et al. (2017)]
[Image source: He et al. (2017)]