
Recommender systems with Python - (5) Memory-based collaborative filtering - 2
08 Aug 2020 | Python Recommender systems Collaborative filteringIn the previous posting, we reviewed key ideas of and intuition behind the memory-based (a.k.a neighborhood/heuristic) methods. The crux of most memory-based methods are the concept of “neighborhood,” which is a set of instances that are close, or similar, to each other. Thus, in this posting, let’s see how we measure and compute the level of similarity between users and items.
User-item interaction matrix
As in most data mining problems, it is convenient to think users and items as vectors in a user-item interaction matrix. Assume that we are building a movie recommender system. We just started to build it, so there are only five users now, who are Tony, Willie, Wiggum, Nelson, and Krusty (BTW, these are my favorite characters in Simpsons. Don’t ask why lol). They rated six movies, which are The Godfather, Inception, Leon, The Departed, Pulp Fiction, and Forrest Gump, in a 10-point scale. Once we get data regarding their ratings information, we need to record such data in some consistent format. The most common approach to record such information is creating a table using spreadsheets such as below.
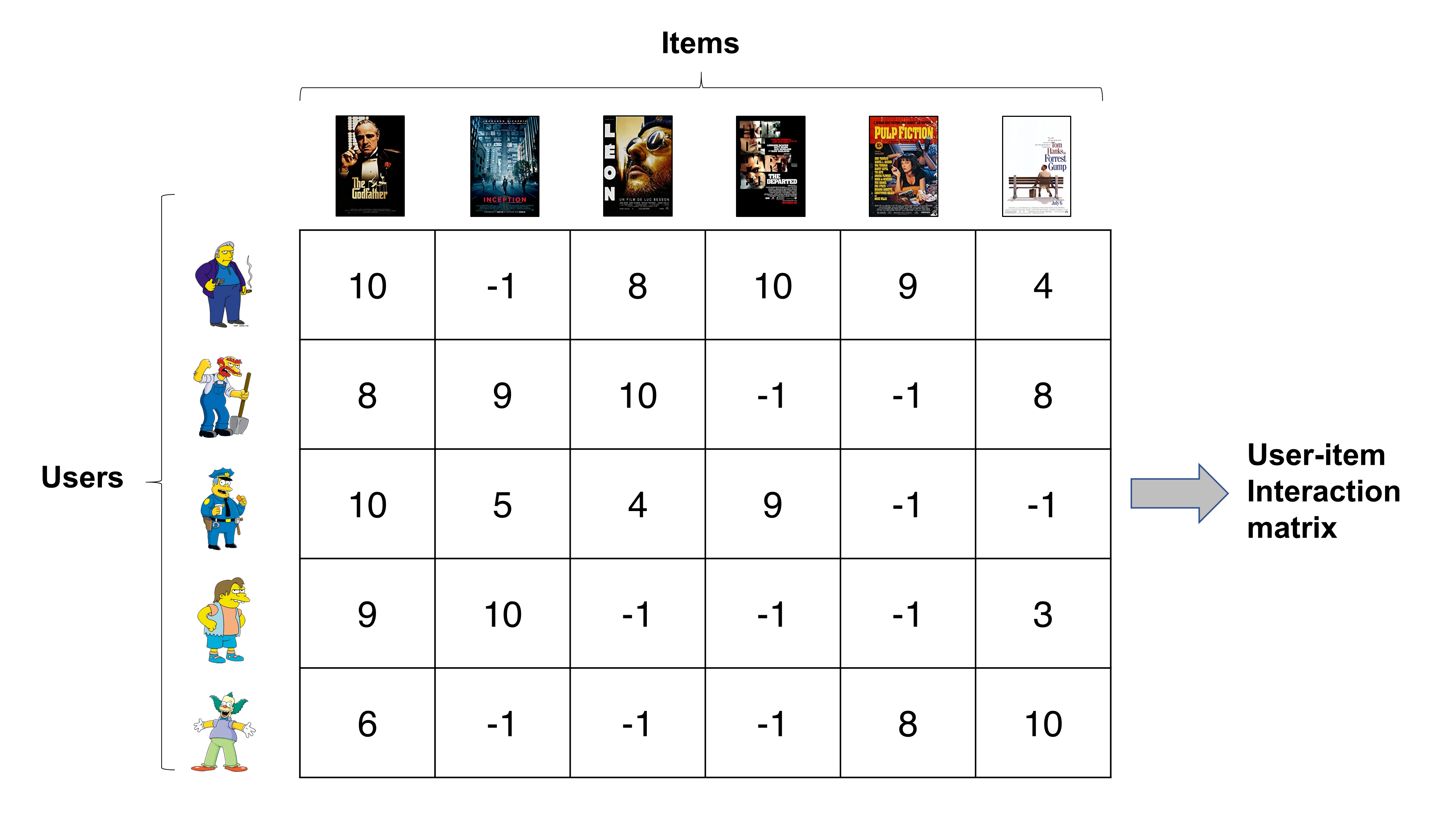
Each row pertains to a user and each column is for a movie. And each element in the table shows rating information by a user in the corresponding row of a movie in the corresponding column. For instance, the number in the first row, third column is Tony’s ratings of the movie Leon, which is 8 out of 10. And the number in the fourth row, sixth column is Nelson’s rating for the movie Forrest Gump. Now, the rating information indicates how users interacted with movies, i.e., items. Hence, user-item interaction matrix is essentially a fancy name for this table. So don’t be afraid of technical terms “interaction” or “matrix” - even you can create a small user-item interaction matrix using Excel or Google Sheets.
Missing values, sparsity, and implicit/explicit feedbacks
If you have a second look at the table above, you will see that some entries have negative values, i.e., -1. This is where there is no rating information. In other words, the user has not rated the item. For example, Tony hasn’t rated the movie Inception and Wille hasn’t rated the movies the Departed and Pulp Fiction. I set the value to -1 to distinguish from ratings that have positive values. You can use any other value, given that it is distinguished from ratings.
If there are much more missing values than positive values, we have a sparsity problem. The matrix is so sparse that it is difficult to derive meaningful collaborative patterns from it. The sparsity problem is prevalent in practice. In many cases, it is difficult to obtain explicit feedbacks such as ratings. For instance, only a fraction of purchasers at Amazon.com leave ratings and reviews. Even though we know they purchased an item, we don’t know whether they were satisfied with the item or not. And that is why they ask us to leave ratings after the purchase as below. But to be honest, I rarely leave reviews. Sorry! But there are many people like me, exacerbating the sparsity problem.
Thus, in many practical cases, we rely on implicit feedbacks, which are subtle cues that indicate the user’s preference. The number of revisits to a movie page and search history can be good examples of implicit feedbacks. But here, let’s just focus on explicit feedbacks, since they are most straightforward to model. We can come back to implicit feedbacks after we familiarize with explicit feedbacks.
Users and items as vectors
Now, let’s come back to the point that users and items can be represented as vectors. For instance, a vector for Tony in the matrix is $v_{tony} = (10, -1, 8, 10, 9, 4)$ and a vector for Krusty the clown is $v_{krusty} = (6, -1, -1, -1, 8, 10)$. Similarly, vectors for movies can be obtained by column-wise slicing of the matrix. The key advantage of doing this is that we can perform various arithmetic operations and optimization tasks.

{kind=link}
A simplest way to obtained a distance between two users (or items) is to subtract one vector from another and sum the absolute values. This is called Mahattan distance. The intuition behind is pretty self-explanatory. The absolute value of element-wise subtraction is the difference in ratings to that movie by both users. For instance, since Tony gave 10 scores to The Godfather and Krusty gave 6, the absolute difference is 4. In more mathematical terms, the distance in The Godfather dimension is 4. Therefore, we are summing up distances in each dimension, i.e., each movie, to obtain an aggregated distance for all movies.
\begin{equation} |v_{tony} - v_{krusty}| = |(4, -1, -1, -1, 1, 6)| = 11 \end{equation}
One thing to note is that we are only considering the movies both Tony and Krusty gave ratings to, i.e., The Godfather, Pulp Fiction, and Forrest Gump. We cannot calculate distance for the movie that either of them did not give ratings to. This is why high sparsity can be a thorny problem - more missing values implies less dimensions can be taken into account.
As mentioned, the Manhattan distance is one of the simplest method to calculate the distance. I used it in this posting to provide intuitiion to the concept of similarity and distance. Of course there are many distance metrics that are more sophisticated than that. We will see them in the next posting!
References
- Ricci, F., Rokach, L., & Shapira, B. (2011). Introduction to recommender systems handbook. In Recommender systems handbook (pp. 1-35). Springer, Boston, MA.
- Koren, Y., Bell, R., & Volinsky, C. (2009). Matrix factorization techniques for recommender systems. Computer, 42(8), 30-37.