
Attention in Neural Networks - 8. Alignment Models (1)
05 Mar 2020 | Attention mechanism Deep learning PytorchAttention Mechanism in Neural Networks - 8. Alignment Models (1)
So far, we looked into Seq2Seq, or the RNN Encoder-Decoder, proposed by Cho et al. (2014) and Sutskever et al. (2014). Seq2Seq is a powerful deep learning architecture to model variable-length sequence data. However, Bahdahanu et al. (2015) suggested one shortcoming of the need to compress all information from a souce sentence.
“A potential issue with this encoder–decoder approach is that a neural network needs to be able to compress all the necessary information of a source sentence into a fixed-length vector. This may make it difficult for the neural network to cope with long sentences, especially those that are longer than the sentences in the training corpus” (Bahdahanu et al. 2015)
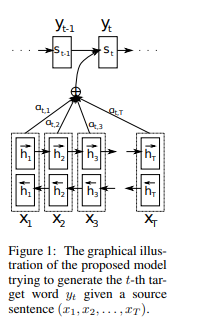 [Image source: Bahdahanu et al. (2015)]
[Image source: Bahdahanu et al. (2015)]
Such shortcoming leads to a potential loss of information, especially in case of long sentences as noted. Therefore, Bahdahanu et al. (2015) proposed an improve sequence-to-sequence architecture that aligns source and target sequences. This will enable the model to attend to a specific part of the source sentence, minimizing information loss from long sentences. In addition, such mechanism enables explanations of mapping between the source and target as in saliency maps below.
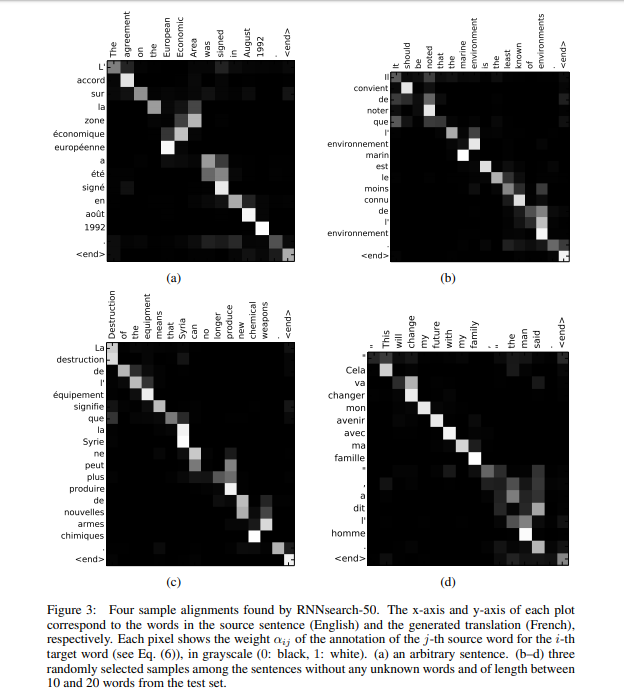 [Image source: Bahdahanu et al. (2015)]
[Image source: Bahdahanu et al. (2015)]
In this posting, let’s briefly go through the alignment mechanism for input and output sequences proposed by Bahdahanu et al. (2015).
Encoder
The encoder is trained almost identically to the encoder in the Seq2Seq model. One slight difference is that the hidden state in each step in the source sequence should be memorized to align with the target sequence. $ h_t $ and $x_t$ are notations for the hidden state and source input at the step $t$. And the RNN in the encoder is noted as the function $f$. Therefore, each hidden state is calculated as below. Note that Bahdahanu et al. (2015) utilize bidirectional RNN to effectively model natural language sentences.
\begin{equation} h_t = f(x_t, h_{t-1}), t = 2, 3, …, n \end{equation}
Decoder
The decoder is slightly tweaked to align source and target states. To distiguish from the encoder, the hidden state and target output at the step $t$ are noted as $s_t$ and $y_t$. The context vector at each step is a weighted sum of the hidden states from the encoder.
\begin{equation} c_i = \sum_{j=1}^{n} \alpha_{ij}h_j \end{equation}
The weights at each step of the decoder is trained by a single dense layer applied by a softmax function to normalize the outputs.
\begin{equation}
\begin{split}
\alpha_{ij} = \frac{exp(e_{ij})}{\sum_{t=1}^{n}exp(e_{it})}
e_{ij} = dense(s_{i-1}, h_j)
\end{split}
\end{equation}
The dense layer here is an alignment model that aligns the source and target.
“an alignment model which scores how well the inputs around position j and the output at position i match.” (Bahdahanu et al. 2015)
In this posting, we briefly looked into the architecture of Seq2Seq with alignment proposed by Bahdahanu et al. (2015). From the next posting, let’s try implementing it with Pytorch. Thank you for reading.