
Attention in Neural Networks - 14. Various attention mechanisms (3)
20 Mar 2020 | Attention mechanism Deep learning PytorchAttention Mechanism in Neural Networks - 14. Various attention mechanisms (3)
So far, we looked into and implemented scoring functions outlined by Luong et al. (2015). In this posting, let’s have a look at local attention that was proposed in the same paper.
Local attention
As mentioned in previous postings, local attention differs from global attention in that it attends to local inputs that are in the vicinity of the aligned position. There are two methods that are suggested to find the aligned position - i.e., monotonic alignment (local-m) and predictive alignment (local-p). Though the mathematical details and implementation differ, motivations and intuition behind the two are largely similar. Here, let’s examine local-m, which is simpler and more intuitive.
Below diagram illustrates an example of applying local-m to a real-world task of translating a French (source) sentence to an English (target) sentence. Consider translating a french sentence “Non, Je ne regrette rien”, which was also a soundtrack of the movie inception. A correct translation is “No, I do not regret anything” in English.
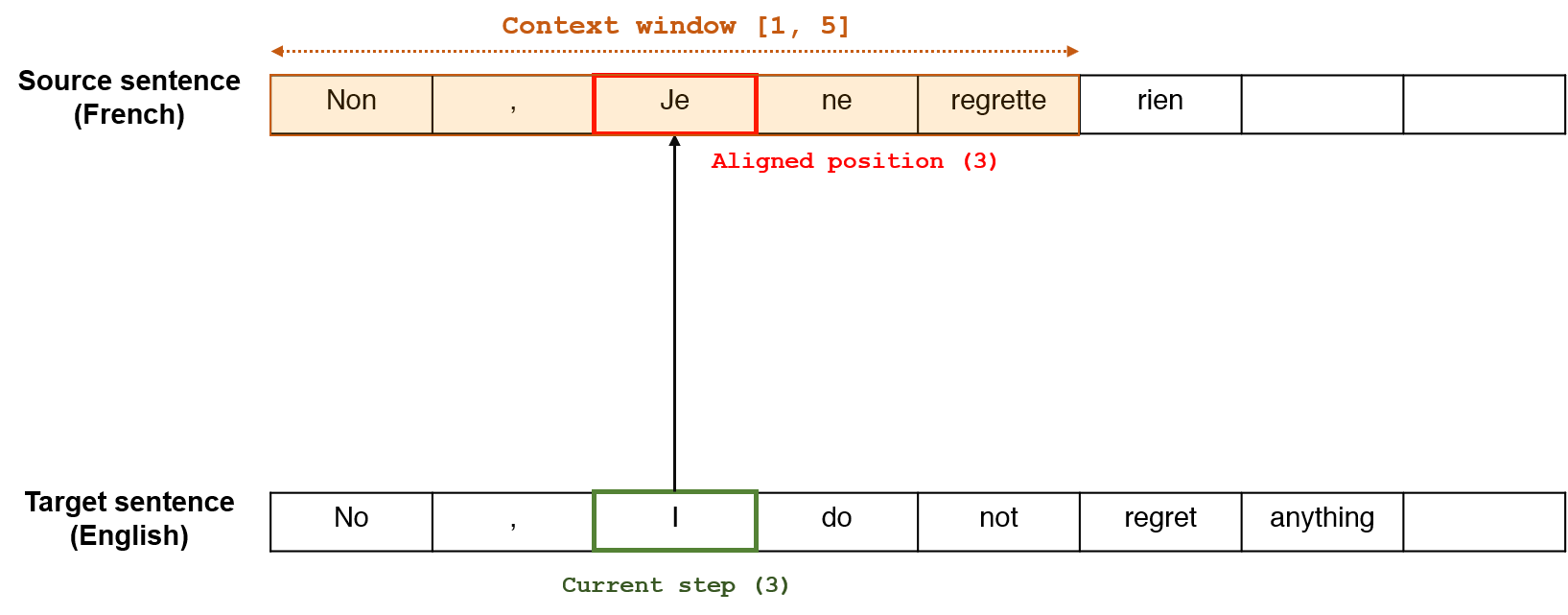
Let us set $D = 2$, which can be empirically selected by a developer. Consider the third step of the target sentence, where we have the word “I”. Since for local-m, we regard $p_t = t$, the aligned position is also 3, which has the word “Je” in the source sentence. This is also common-sensical since the direct translation of the French word “Je” is “I”. And since we set $D = 2$, the context window is $[1, 5]$, which comprises the words “Non, Je ne regrette”. Therefore, the decoder at the third step attends to that part of the source sentence for alignment. Then, the same scoring and normalization procedure can be applied as global attention we investigated so far.
Pytorch implementation of local-m
Now, let’s try implementing local-m with Pytorch. As we can apply the same scoring and normalization procedure, we do not need to convert the source code for the encoder and decoder that we implemented before. The only part that we need to modify is the training process to find the context window for each step in the target. One approach that we can take is set the window size $D$ and select surrounding encoder outputs at each step. The base case would be setting $[p_t-D, p_t+D]$ to include $2D+1$ encoder states.
enc_outputs_selected = enc_outputs[l-WINDOW_SIZE:l+WINDOW_SIZE+1]
However, there are edge cases that we should meticulously attend to. There are two edge cases at (1) the start of the sentence and (2) the end of the sentence, where we cannot select surrounding $2D+1$ steps. For instance, at the French-English translation example above, we cannot set the full context window of length five for the first and second target words (“Non” and ”,”). So, let’s add if-elif-else to fully consider both base and edge cases.
for l in range(target.size(0)):
if l < WINDOW_SIZE:
enc_outputs_selected = enc_outputs[:l+WINDOW_SIZE+1]
elif l > target.size(0) - WINDOW_SIZE - 1:
enc_outputs_selected = enc_outputs[l-WINDOW_SIZE:]
else:
enc_outputs_selected = enc_outputs[l-WINDOW_SIZE:l+WINDOW_SIZE+1]
Training local attention
Below is the complete code for training local attention models. Also note that we have to define an additional hyperparameter WINDOW_SIZE that denotes the size of the context window ($D$).
%%time
encoder_opt = torch.optim.Adam(encoder.parameters(), lr = 0.01)
decoder_opt = torch.optim.Adam(decoder.parameters(), lr = 0.01)
criterion = nn.NLLLoss()
loss = []
weights = []
for i in tqdm(range(NUM_EPOCHS)):
for j in range(len(eng_sentences)):
current_weights = []
source, target = eng_sentences[j], deu_sentences[j]
source = torch.tensor(source, dtype = torch.long).view(-1, 1).to(DEVICE)
target = torch.tensor(target, dtype = torch.long).view(-1, 1).to(DEVICE)
current_loss = 0
h0 = torch.zeros(1, 1, encoder.hidden_size).to(DEVICE)
encoder_opt.zero_grad()
decoder_opt.zero_grad()
enc_outputs = torch.zeros(MAX_SENT_LEN, encoder.hidden_size).to(DEVICE)
for k in range(source.size(0)):
_, h0 = encoder(source[k].unsqueeze(0), h0)
enc_outputs[k] = h0.squeeze()
# monotonic alignment
dec_input = torch.tensor([[deu_words.index("<sos>")]]).to(DEVICE)
for l in range(target.size(0)):
if l < WINDOW_SIZE:
enc_outputs_selected = enc_outputs[:l+WINDOW_SIZE+1]
elif l > target.size(0) - WINDOW_SIZE - 1:
enc_outputs_selected = enc_outputs[l-WINDOW_SIZE:]
else:
enc_outputs_selected = enc_outputs[l-WINDOW_SIZE:l+WINDOW_SIZE+1]
out, h0, w = decoder(dec_input, h0, enc_outputs_selected)
_, max_idx = out.topk(1)
dec_input = max_idx.squeeze().detach()
current_loss += criterion(out, target[l])
if dec_input.item() == deu_words.index("<eos>"):
break
current_loss.backward(retain_graph=True)
encoder_opt.step()
decoder_opt.step()
# weights.append(current_weights)
loss.append(current_loss.item()/(j+1))
In this posting, we implemented local attention proposed by Luong et al. (2015). Thank you for reading.