
Attention in Neural Networks - 18. Transformer (2)
20 Apr 2020 | Attention mechanism Deep learning PytorchAttention Mechanism in Neural Networks - 18. Transformer (2)
In the previous posting, we have gone through the details of the Transformer architecture proposed by Vaswani et al. (2017). From now on, let’s see how we can implement the Transformer network in Pytorch, using nn.Transformer. The details of Transformer can be very complicated and daunting. However, with some background knowledge obtained from the previous posting and nn.Transformer’s help, it is not so difficult.
Data import & preprocessing
We come back to the English-German machine translation dataset from manythings.org. If you are new here and interested in details, please refer to my previous postings on Seq2Seq.
Using Jupyter Notebook or Google Colaboratory, the data file can be fetched directly from the Web and unzipped.
!wget https://www.manythings.org/anki/deu-eng.zip
!unzip deu-eng.zip
with open("deu.txt") as f:
sentences = f.readlines()
As we did before, let’s randomly sample 10,000 instances and process them.
NUM_INSTANCES = 10000
MAX_SENT_LEN = 10
eng_sentences, deu_sentences = [], []
eng_words, deu_words = set(), set()
for i in tqdm(range(NUM_INSTANCES)):
rand_idx = np.random.randint(len(sentences))
# find only letters in sentences
eng_sent, deu_sent = ["<sos>"], ["<sos>"]
eng_sent += re.findall(r"\w+", sentences[rand_idx].split("\t")[0])
deu_sent += re.findall(r"\w+", sentences[rand_idx].split("\t")[1])
# change to lowercase
eng_sent = [x.lower() for x in eng_sent]
deu_sent = [x.lower() for x in deu_sent]
eng_sent.append("<eos>")
deu_sent.append("<eos>")
if len(eng_sent) >= MAX_SENT_LEN:
eng_sent = eng_sent[:MAX_SENT_LEN]
else:
for _ in range(MAX_SENT_LEN - len(eng_sent)):
eng_sent.append("<pad>")
if len(deu_sent) >= MAX_SENT_LEN:
deu_sent = deu_sent[:MAX_SENT_LEN]
else:
for _ in range(MAX_SENT_LEN - len(deu_sent)):
deu_sent.append("<pad>")
# add parsed sentences
eng_sentences.append(eng_sent)
deu_sentences.append(deu_sent)
# update unique words
eng_words.update(eng_sent)
deu_words.update(deu_sent)
eng_words, deu_words = list(eng_words), list(deu_words)
# encode each token into index
for i in tqdm(range(len(eng_sentences))):
eng_sentences[i] = [eng_words.index(x) for x in eng_sentences[i]]
deu_sentences[i] = [deu_words.index(x) for x in deu_sentences[i]]
idx = 10
print(eng_sentences[idx])
print([eng_words[x] for x in eng_sentences[idx]])
print(deu_sentences[idx])
print([deu_words[x] for x in deu_sentences[idx]])
If properly imported and processed, you will get an output something like this. But specific values of output will be somewhat different since we are randomly sampling instances.
[2142, 1843, 174, 3029, 1716, 3449, 4385, 2021, 4359, 4359]
['<sos>', 'tom', 'didn', 't', 'have', 'a', 'chance', '<eos>', '<pad>', '<pad>']
[2570, 6013, 2486, 2470, 1631, 2524, 3415, 3415, 3415, 3415]
['<sos>', 'tom', 'hatte', 'keine', 'chance', '<eos>', '<pad>', '<pad>', '<pad>', '<pad>']
Setting Parameters
Most of paramter setting is similar to the RNN Encoder-Decoder network and its variants.
HIDDEN SIZE: previously this was used to set the number of hidden cells in the RNN network. However, here it will be used to set the dimensionality of the feedforward network, or the dense layers.NUM_LAYERS: similary, instead of setting the number of RNN layers, this is used to determine the number of dense layers.NUM_HEADS: this is a new parameter used to determine the number of heads in multihead attention. If you are unsure what multihead attention is, refer to the previous posting.
ENG_VOCAB_SIZE = len(eng_words)
DEU_VOCAB_SIZE = len(deu_words)
NUM_EPOCHS = 10
HIDDEN_SIZE = 16
EMBEDDING_DIM = 30
BATCH_SIZE = 128
NUM_HEADS = 2
NUM_LAYERS = 3
LEARNING_RATE = 1e-2
DEVICE = torch.device('cuda')
Creating dataset and dataloader
This is exactly the same step as before, so I won’t explain the details. Again, if you want to know more, please refer to the previous postings.
class MTDataset(torch.utils.data.Dataset):
def __init__(self):
# import and initialize dataset
self.source = np.array(eng_sentences, dtype = int)
self.target = np.array(deu_sentences, dtype = int)
def __getitem__(self, idx):
# get item by index
return self.source[idx], self.target[idx]
def __len__(self):
# returns length of data
return len(self.source)
np.random.seed(777) # for reproducibility
dataset = MTDataset()
NUM_INSTANCES = len(dataset)
TEST_RATIO = 0.3
TEST_SIZE = int(NUM_INSTANCES * 0.3)
indices = list(range(NUM_INSTANCES))
test_idx = np.random.choice(indices, size = TEST_SIZE, replace = False)
train_idx = list(set(indices) - set(test_idx))
train_sampler, test_sampler = SubsetRandomSampler(train_idx), SubsetRandomSampler(test_idx)
train_loader = torch.utils.data.DataLoader(dataset, batch_size = BATCH_SIZE, sampler = train_sampler)
test_loader = torch.utils.data.DataLoader(dataset, batch_size = BATCH_SIZE, sampler = test_sampler)
Transformer network in (almost) 10 lines of code
As mentioned, implementing a Transformer network is simple and straightforward. With around 10 lines of code, a simple and straightfoward Transformer network for sequence-to-sequence modeling can be created.
class TransformerNet(nn.Module):
def __init__(self, num_src_vocab, num_tgt_vocab, embedding_dim, hidden_size, nhead, n_layers):
super(TransformerNet, self).__init__()
self.enc_embedding = nn.Embedding(num_src_vocab, embedding_dim)
self.dec_embedding = nn.Embedding(num_tgt_vocab, embedding_dim)
self.transformer = nn.Transformer(d_model = embedding_dim, nhead = nhead, num_encoder_layers=n_layers, num_decoder_layers = n_layers, dim_feedforward = hidden_size, dropout = dropout)
self.dense = nn.Linear(embedding_dim, num_tgt_vocab)
self.log_softmax = nn.LogSoftmax()
def forward(self, src, tgt):
src, tgt = self.enc_embedding(src), self.dec_embedding(tgt)
x = self.transformer(src, tgt)
return self.log_softmax(self.dense(x))
model = TransformerNet(ENG_VOCAB_SIZE, DEU_VOCAB_SIZE, EMBEDDING_DIM, HIDDEN_SIZE, NUM_HEADS, NUM_LAYERS, DROPOUT).to(DEVICE)
criterion = nn.NLLLoss()
optimizer = torch.optim.Adam(model.parameters(), lr = LEARNING_RATE)
After creating the model, it can be trained and evaluated the same way as the previous ones.
%%time
loss_trace = []
for epoch in tqdm(range(NUM_EPOCHS)):
current_loss = 0
for i, (x, y) in enumerate(train_loader):
x, y = x.to(DEVICE), y.to(DEVICE)
outputs = model(x, y)
loss = criterion(outputs.permute(0, 2, 1), y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
current_loss += loss.item()
loss_trace.append(current_loss)
# loss curve
plt.plot(range(1, NUM_EPOCHS+1), loss_trace, 'r-')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.show()
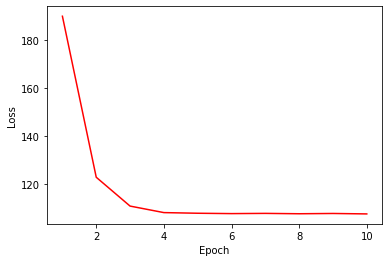
Is this it?
We implemented a quick and easy, yet extremely powerful neural networks model for sequence to sequence modeling. However, there is more to it. For instance, we didn’t include the positioning encoding, which is a critical element of Transformer. Also, the building blocks of nn.Transformer can be decomposed and modified for better performance and more applications. And there are a number of parameters that can be fine-tuned for optimal performance. So, from the next posting, let’s have a deeper look under the hood of nn.Transformer.