
Attention in Neural Networks - 22. BERT (1) Introduction to BERT (Bidirectional Encoder Representations from Transformers)
24 Jul 2020 | Attention mechanism Deep learning Pytorch BERT TransformerAttention Mechanism in Neural Networks - 22. BERT (1)
In a few previous postings, we looked into Transformer and tried implementing it in Pytorch. However, as we have seen in this posting, implementing and training a Transformer-based deep learning model from scratch is challenging and requires lots of data and computational resources. Fortunately, we don’t need to train the model from scratch every time. Transformer-based pre-trained models such as BERT and OpenAI GPT are readily available from Python packages such as transformers by HuggingFace. Utilizing those pre-trained models, we can achieve state-of-the-art (SOTA) performances in various natural language understanding tasks in record time!

As explained in earlier postings, BERT (Bidirectional Encoder Representations from Transformers) is one of the pioneering methods for pre-training with Transformer- and attention-inspired deep learning models. It showed SOTA results in a number of tasks in 2019 and opened a new era of natural language processing. Since then, many Transformer-based language models such as XLNet, RoBERTa, DistillBERT, and ALBERT, have been proposed. All those variants have slightly different architectures from each other, but it is easier to grasp and apply any of them for your project if you have a firm understanding of BERT.
So in this posting, let’s start with understanding the great BERT achitecture!
Supervised learning and unsupervised learning
In the abstract, BERT combines unsupervised learning and supervised learning to provide a generic language model that can be used for virtually any NLP task. Many of you would know, but just for recap, unsupervised learning is inferring patterns in the data without a definite target label. Techniques to explore distibutions in data such as clustering analysis and principal component analysis are classic examples of unsupervised learning techniques. In contrast, supervised learning is concerned with predicting a labeled target responses. Classification and regression are two major tasks in supervised learning. Many machine learning models such as linear/logistic regression, decision trees, and support vector machines can be used for both classification and regression.
Unsupervised word embedding models such as Word2vec and GloVe have become an indispensable part of contemporary NLP systems. However, despite being highly effective in representing semantics and syntactic regularities, they are not trained in an end-to-end manner. That is, a separate classifier using pre-trained embeddings as input features has to be trained. Therefore, more recent methods have been increasingly training the embeddings and classifier simultaneously in a single neural network architecture (e.g., Kim 2014).
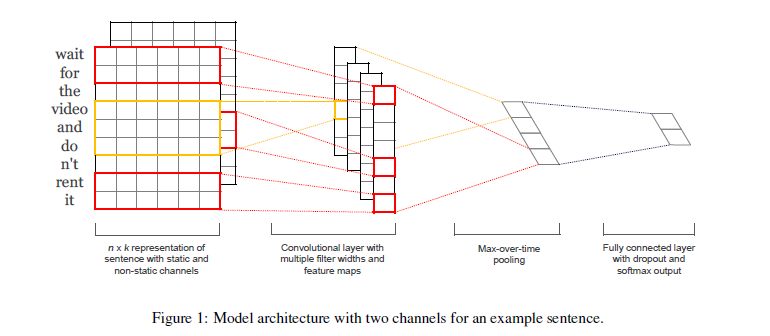 [Kim 2014]
[Kim 2014]
Each of the two methods has own pros and cons. We can train word embedding models with a tremendously large unlabled text data, capturing as many language features as possible. Also, the trained embeddings are generalizable - it can be used for virtually any downstream tasks. However, this is based on a strong assumption that syntactic and semantic patterns in corpora are largely similar across different tasks and datasets. Our common sense argues that this is not always the case. Even when the same person is writing, languages used for different tasks and objectives can differ significantly. For instance, vocabularies that I use for Amazon reviews or Tweets will be dramatically different from those that I use for these kind of postings or manuscripts for academic journals.
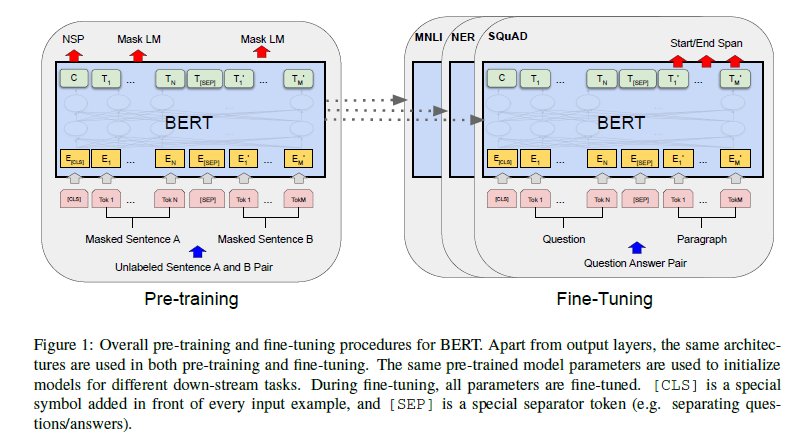 [Devlin et al. 2019]
[Devlin et al. 2019]
BERT overcomes this challenge by combining unsupervised pre-training and supervised fine-tuning. That is, the word and sentence embeddings are first trained with large-scale, generic text data. The Transformer architecture is utilized here for better representation. Then, the overall model including the embeddings is fine-tuned while performing downstream tasks such as question answering.
Transfer learning
As a result, a single BERT model can achieve a remarkable performance in not only one task but in many NLP tasks. A direct application of this property is transfer learning. Transfer learning, or knowledge transfer, is concerned with transferring knowledge from one domain from another. Generally, one has sufficient labeled training data in the former but not in the latter (Pan and Yang 2010).
Transfer learning has been actively researched and utilized in the image recognition field as well. In their seminal work, Zeiler and Fergus (2014) showed that different filters of convolutional neural networks (CNN) learn distinct features that are activated by common motifs in multiple images. For instance, The first layer below learns low-level features such as colors and edges, wheareas the fourth and fifth layers learn more abstract concepts such as dogs and wheels. It has become a standard practice in image recognition to utilize pre-trained CNNs with large-scale datasets such as ImageNet. FYI, Pytorch provides pretrained CNN models such as AlexNet and GoogleNet.
 [Zeiler and Fergus 2014]
[Zeiler and Fergus 2014]
BERT can be used to transfer knowledge from one domain to another. Similar to using pre-trained convolutional layers for object detection or image classification, one can use pre-trained embedding layers that have been already used for other tasks. This has the potential to significantly reduce the cost of gathering and labeling new training data and improve text representations.
In this posting, we had a brief introduction to BERT for intuitive understanding. In the following postings, let’s dig deeper into the key components of BERT.