
케라스와 함께하는 쉬운 딥러닝 (3) - 다층 퍼셉트론 3 (Training MLP with MNIST Dataset)
22 Apr 2018 | Python Keras Deep Learning 케라스다층 퍼셉트론 3 (Training MLP with MNIST Dataset)
Objective: MNIST 데이터 셋을 불러와 이를 다층 퍼셉트론 모델에 적합한 형태로 변형하여 학습시킨다.
MNIST 데이터 셋
인공신경망에 대해 배울 때 흔히 사용되는 토이 데이터 셋(toy dataset) 중 하나며, 사람들이 직접 손으로 쓴 0부터 9까지의 숫자를 이미지화한 데이터이다. 6만 개의 학습 데이터와 1만 개의 검증 데이터로 구축되어 있다.
- source: THE MNIST DATABASE

MNIST 데이터 셋 불러오기
# 케라스에 내장된 mnist 데이터 셋을 함수로 불러와 바로 활용 가능하다
from keras.datasets import mnist
import matplotlib.pyplot as plt
(X_train, y_train), (X_test, y_test) = mnist.load_data()
plt.imshow(X_train[0]) # show first number in the dataset
plt.show()
print('Label: ', y_train[0])

plt.imshow(X_test[0]) # show first number in the dataset
plt.show()
print('Label: ', y_test[0])

데이터 셋 전처리
앞서 언급했다시피, MNIST 데이터는 흑백 이미지 형태로, 2차원 행렬(28 X 28)과 같은 형태라고 할 수 있다.

하지만 이와 같은 이미지 형태는 우리가 지금 활용하고자 하는 다층 퍼셉트론 모델에는 적합하지 않다. 다층 퍼셉트론은 죽 늘어놓은 1차원 벡터와 같은 형태의 데이터만 받아들일 수 있기 때문이다. 그러므로 우리는 28 X 28의 행렬 형태의 데이터를 재배열(reshape)해 784 차원의 벡터로 바꾼다.
from keras.utils.np_utils import to_categorical
from sklearn.model_selection import train_test_split
# reshaping X data: (n, 28, 28) => (n, 784)
X_train = X_train.reshape((X_train.shape[0], -1))
X_test = X_test.reshape((X_test.shape[0], -1))
# 학습 과정을 단축시키기 위해 학습 데이터의 1/3만 활용한다
X_train, _ , y_train, _ = train_test_split(X_train, y_train, test_size = 0.67, random_state = 7)
# 타겟 변수를 one-hot encoding 한다
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
(19800, 784) (10000, 784) (19800, 10) (10000, 10)
기본 MLP 모델 학습 및 평가
아무런 개선을 하지 않은 기본 MLP 모델(vanilla MLP)을 생성하여 학습해 본다.
모델 생성 및 학습
각 층의 뉴런의 개수는 50개인 은닉층(hidden layer) 4개를 가지고 있는 다층 퍼셉트론 구조를 생성한다.
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import optimizers
model = Sequential()
model.add(Dense(50, input_shape = (784, )))
model.add(Activation('sigmoid'))
model.add(Dense(50))
model.add(Activation('sigmoid'))
model.add(Dense(50))
model.add(Activation('sigmoid'))
model.add(Dense(50))
model.add(Activation('sigmoid'))
model.add(Dense(10))
model.add(Activation('softmax'))
sgd = optimizers.SGD(lr = 0.001)
model.compile(optimizer = sgd, loss = 'categorical_crossentropy', metrics = ['accuracy'])
history = model.fit(X_train, y_train, batch_size = 256, validation_split = 0.3, epochs = 100, verbose = 0)
모델 학습 결과 시각화
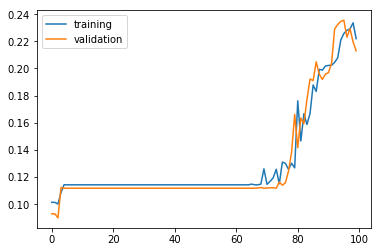
학습이 진행됨에 따라 달라지는 학습 정확도와 검증 정확도의 추이를 시각화해 본다. 60 에포크가 지난 후에 정확도가 올라가기 시작한다.
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.legend(['training', 'validation'], loc = 'upper left')
plt.show()
모델 평가
results = model.evaluate(X_test, y_test)
print('Test accuracy: ', results[1])
학습 정확도 21.44%로 랜덤하게 찍는 경우의 예상 정확도(10%)보다는 높게 나왔지만, 그리 만족스러운 수치는 아니다.
Test accuracy: 0.2144
이미지 인식에 널리 활용되는 CNN (Convolutional Neural Networks) 구조를 활용한 현대 인공 신경망 모델은 MNIST 데이터 셋에서 정확도 99%가 넘는 완벽에 가까운 성능을 보여주고 있다. 그렇지만 아직 우리가 구현한 모델이 보이는 성능은 20%를 간신히 넘기는 수준이다.
이제 다음 포스팅에서 어떻게 우리의 인공 신경망 모델의 MNIST 데이터에 대한 학습을 개선시킬 수 있는지 알아보자.
전체 코드
본 실습의 전체 코드는 여기에서 열람하실 수 있습니다!