
케라스와 함께하는 쉬운 딥러닝 (13) - 다양한 CNN 구조
23 May 2018 | Python Keras Deep Learning 케라스합성곱 신경망 7 - 다양한 CNN 구조
Objective: 케라스로 다양한 CNN 모델을 만들어 본다.
지난 포스팅에서 케라스로 문장 분류를 위한 간단한 CNN 모형을 만들어 보았다.
NLP 계의 MNIST라고 할 수 있을 정도로 자주 활용되는 텍스트 데이터인 IMDB MOVIE REVIEW SENTIMENT 데이터를 활용하였으며, 간단한 1-D CONVOLUTION (TEMPORAL CONVOLUTION)을 적용하여 85% 정도의 검증 정확도를 기록하였다.
이번 포스팅에는 문장 분류를 위한 CNN의 학습 과정을 개선시키고 안정화할 수 있는 여러 가지 방법을 탐구해 보자.
IMDB 데이터 셋 불러오기
IMDB 영화 리뷰 감성분류 데이터 셋(IMDB Movie Revies Sentiment Classification Dataset)은 총 50,000 개의 긍정/혹은 부정으로 레이블링된 데이터 인스턴스(즉, 50,000개의 영화 리뷰)로 이루어져 있으며, 케라스 패키지 내에 processing이 다 끝난 형태로 포함되어 있다.
리뷰 데이터를 불러올 때 주요 파라미터는 아래와 같다
num_features: 빈도 순으로 상위 몇 개의 단어를 포함시킬 것인가를 결정sequence_length: 각 문장의 최대 길이(특정 문장이sequence_length보다 길면 자르고,sequence_length보다 짧으면 빈 부분을 0으로 채운다)를 결정embedding_dimension: 각 단어를 표현하는 벡터 공간의 크기(즉, 각 단어의 vector representation의 dimensionality)
import numpy as np
import matplotlib.pyplot as plt
from keras.datasets import imdb
from keras.preprocessing.sequence import pad_sequences
num_features = 3000
sequence_length = 300
embedding_dimension = 100
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words = num_features)
X_train = pad_sequences(X_train, maxlen = sequence_length)
X_test = pad_sequences(X_test, maxlen = sequence_length)
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
(25000, 300), (25000, 300), (25000,), (25000,)
2-D CONVOLUTION & POOLING
앞서 언급했듯이, 지난번 포스팅에서는 1-D convolution (temporal convolution)을 활용하였다. 이번에는 NLP 과업에서는 자주 활용되지 않지만 이미지 데이터 처리에 자주 활용되는 2-D CONVOLUTION을 적용해 보자.
Reshape을 활용해 embedding layer를 4차원으로 전환해 2차원 합성곱 연산을 가능케 한다.
from keras.layers import Reshape, Conv2D, GlobalMaxPooling2D
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation
from keras import optimizers
def imdb_cnn_2():
model = Sequential()
model.add(Embedding(input_dim = 3000, output_dim = embedding_dimension, input_length = sequence_length))
model.add(Reshape((sequence_length, embedding_dimension, 1), input_shape = (sequence_length, embedding_dimension)))
model.add(Conv2D(filters = 50, kernel_size = (5, embedding_dimension), strides = (1,1), padding = 'valid'))
model.add(GlobalMaxPooling2D())
model.add(Dense(10))
model.add(Activation('relu'))
model.add(Dropout(0.3))
model.add(Dense(10))
model.add(Activation('relu'))
model.add(Dropout(0.3))
model.add(Dense(1))
model.add(Activation('sigmoid'))
adam = optimizers.Adam(lr = 0.001)
model.compile(loss='binary_crossentropy', optimizer=adam , metrics=['accuracy'])
return model
model = imdb_cnn_2()
2차원 합성곱 연산 후에 GlobalMaxPooling2D 레이어를 이어 붙였다(flatten 필요 없음).
history = model.fit(X_train, y_train, batch_size = 50, epochs = 100, validation_split = 0.2, verbose = 0)
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.legend(['training', 'validation'], loc = 'upper left')
plt.show()
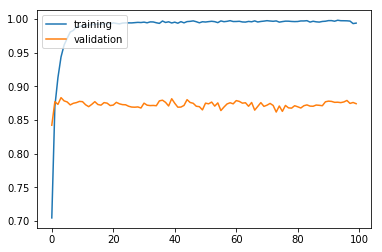
검증 정확도로 모델을 검증해 보자.
results = model.evaluate(X_test, y_test)
print('Test accuracy: ', results[1])
Test accuracy: 0.86628
검증 정확도 86.6%로 지난번에 활용하였던 간단한 모델에 비해서 미묘하게 정확도는 상승하였다.
DIFFERENT FILTER SIZES
지금까지 우리가 구현해온 CONVOLUTION 연산은 한 번에 필터의 사이즈를 하나만 적용하였다. 그렇지만 Kim 2014 논문에서는 하나의 레이어에 여러 개의 크기의 합성곱 필터를 적용한 결과를 이어 붙여 따라 붙는 레이어를 완성하였다.

이번에는 이와 유사하게, 필터 크기를 3, 4, 5로 다양화하고 max pooling을 적용한 결과를 concatenate해 다양한 time window로 학습을 해보자
이를 위해서는 모델을 생성하기 위해 지금까지 사용해왔던 Sequential API가 아닌 Functional API를 사용하여야 한다. Functional API에 대한 자세한 설명은 여기.
from keras.models import Model
from keras.layers import concatenate, Input
filter_sizes = [3, 4, 5]
# 합성곱 연산을 적용하는 함수를 따로 생성. 이렇게 만들어 놓으면 convolution 레이어가 여러개더라도 편리하게 적용할 수 있다.
def convolution()
inn = Input(shape = (sequence_length, embedding_dimension, 1))
convolutions = []
# we conduct three convolutions & poolings then concatenate them.
for fs in filter_sizes:
conv = Conv2D(filters = 100, kernel_size = (fs, embedding_dimension), strides = 1, padding = "valid")(inn)
nonlinearity = Activation('relu')(conv)
maxpool = MaxPooling2D(pool_size = (sequence_length - fs + 1, 1), padding = "valid")(nonlinearity)
convolutions.append(maxpool)
outt = concatenate(convolutions)
model = Model(inputs = inn, outputs = outt)
return model
def imdb_cnn_3():
model = Sequential()
model.add(Embedding(input_dim = 3000, output_dim = embedding_dimension, input_length = sequence_length))
model.add(Reshape((sequence_length, embedding_dimension, 1), input_shape = (sequence_length, embedding_dimension)))
# call convolution method defined above
model.add(convolution())
model.add(Flatten())
model.add(Dense(10))
model.add(Activation('relu'))
model.add(Dropout(0.3))
model.add(Dense(10))
model.add(Activation('relu'))
model.add(Dropout(0.3))
model.add(Dense(1))
model.add(Activation('sigmoid'))
adam = optimizers.Adam(lr = 0.001)
model.compile(loss='binary_crossentropy', optimizer=adam , metrics=['accuracy'])
return model
model = imdb_cnn_3()
모델을 학습시키고 검증해 보자
history = model.fit(X_train, y_train, batch_size = 50, epochs = 100, validation_split = 0.2, verbose = 0)
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.legend(['training', 'validation'], loc = 'upper left')
plt.show()
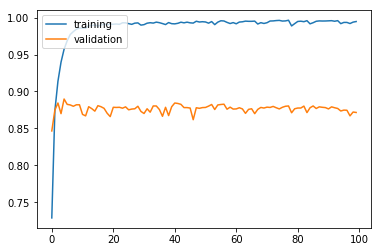
results = model.evaluate(X_test, y_test)
print('Test accuracy: ', results[1])
검증 정확도 87.2%로 기본 모델(baseline model)에 비해 2% 가량 상승하였다.
Test accuracy: 0.87284
전체 코드
본 실습의 전체 코드는 여기에서 열람하실 수 있습니다!