
Attention in Neural Networks - 9. Alignment Models (2)
06 Mar 2020 | Attention mechanism Deep learning PytorchAttention Mechanism in Neural Networks - 9. Alignment Models (2)
In the previous posting, we briefly went through the Seq2Seq architecture with alignment proposed by Bahdahanu et al. (2015). In this posting, let’s see how we can implement such models in Pytorch.
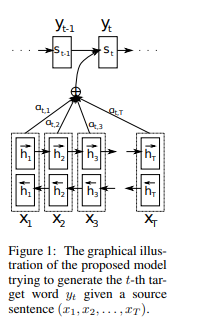 [Image source: Bahdahanu et al. (2015)]
[Image source: Bahdahanu et al. (2015)]
Import packages and dataset
Here, we will again use the English-German machine translation dataset. So, the code will be largely identical to previous postings.
import re
import torch
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
from matplotlib import pyplot as plt
from tqdm import tqdm
!wget https://www.manythings.org/anki/deu-eng.zip
!unzip deu-eng.zip
with open("deu.txt") as f:
sentences = f.readlines()
Preprocessing data
This is also the same as previous postings for Seq2Seq. Let’s randomly sample 10,000 instances for computational efficiency.
NUM_INSTANCES = 10000
eng_sentences, deu_sentences = [], []
eng_words, deu_words = set(), set()
for i in tqdm(range(NUM_INSTANCES)):
rand_idx = np.random.randint(len(sentences))
# find only letters in sentences
eng_sent, deu_sent = ["<sos>"], ["<sos>"]
eng_sent += re.findall(r"\w+", sentences[rand_idx].split("\t")[0])
deu_sent += re.findall(r"\w+", sentences[rand_idx].split("\t")[1])
# change to lowercase
eng_sent = [x.lower() for x in eng_sent]
deu_sent = [x.lower() for x in deu_sent]
eng_sent.append("<eos>")
deu_sent.append("<eos>")
# add parsed sentences
eng_sentences.append(eng_sent)
deu_sentences.append(deu_sent)
# update unique words
eng_words.update(eng_sent)
deu_words.update(deu_sent)
eng_words, deu_words = list(eng_words), list(deu_words)
# encode each token into index
for i in tqdm(range(len(eng_sentences))):
eng_sentences[i] = [eng_words.index(x) for x in eng_sentences[i]]
deu_sentences[i] = [deu_words.index(x) for x in deu_sentences[i]]
print(eng_sentences[0])
print([eng_words[x] for x in eng_sentences[0]])
print(deu_sentences[0])
print([deu_words[x] for x in deu_sentences[0]])
[3401, 4393, 3089, 963, 3440, 3778, 3848, 3089, 2724, 1997, 1189, 3357]
['<sos>', 'when', 'i', 'was', 'crossing', 'the', 'street', 'i', 'saw', 'an', 'accident', '<eos>']
[3026, 3, 4199, 6426, 7012, 5311, 5575, 4199, 4505, 6312, 4861]
['<sos>', 'als', 'ich', 'die', 'straße', 'überquerte', 'sah', 'ich', 'einen', 'unfall', '<eos>']
Set hyperparameters
The hyperparameters that should be defined are also very similar to the settings in Seq2Seq. For convenience, we set the maximum sentence length to be the length of the longest sentence among source sentences.
MAX_SENT_LEN = len(max(eng_sentences, key = len))
ENG_VOCAB_SIZE = len(eng_words)
DEU_VOCAB_SIZE = len(deu_words)
NUM_EPOCHS = 10
HIDDEN_SIZE = 16
EMBEDDING_DIM = 30
DEVICE = torch.device('cuda')
Encoder and Decoder
The encoder is very similar to Seq2Seq, but with a slight difference. As mentioned in the previous posting, we have to memorize the hidden states of all steps in source to align them with those in target. Therefore, we feed each input to the embedding and GRU layers to reserve the outputs.
class Encoder(nn.Module):
def __init__(self, vocab_size, hidden_size, embedding_dim):
super(Encoder, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.gru = nn.GRU(embedding_dim, hidden_size)
def forward(self, x, h0):
x = self.embedding(x).view(1, 1, -1)
out, h0 = self.gru(x, h0)
return out, h0
The decoder is also similar, but has an additional mechanism for alignment. Also, it has an additional input for hidden states from the encoder (encoder_hidden_state). In a for loop inside the forward() function, aligned weights for each source hidden state is calculated. The weights are saved to the variable aligned_weights. Then the weights are normalized with a softmax function (F.softmax()) and multiplied with the encoder hidden states to generate a context vector. It should be noted that many implementations of Bahdanau attention includes a tanh function and an additional parameter v to be jointly trained, but I did not include them for simplicity.
class Decoder(nn.Module):
def __init__(self, vocab_size, hidden_size, embedding_dim, device):
super(Decoder, self).__init__()
self.hidden_size = hidden_size
self.device = device
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.attention = nn.Linear(hidden_size + hidden_size, 1)
self.gru = nn.GRU(hidden_size + embedding_dim, hidden_size)
self.dense = nn.Linear(hidden_size, vocab_size)
self.log_softmax = nn.LogSoftmax(dim = 1)
def forward(self, decoder_input, current_hidden_state, encoder_hidden_state):
decoder_input = self.embedding(decoder_input).view(1, 1, -1)
aligned_weights = torch.randn(encoder_hidden_state.size(0)).to(self.device)
for i in range(encoder_hidden_state.size(0)):
aligned_weights[i] = self.attention(torch.cat((current_hidden_state.squeeze(0), encoder_hidden_state[i].unsqueeze(0)), dim = 1)).squeeze()
aligned_weights = F.softmax(aligned_weights.unsqueeze(0), dim = 1)
context_vector = torch.bmm(aligned_weights.unsqueeze(0), encoder_hidden_state.view(1, -1 ,self.hidden_size))
x = torch.cat((context_vector[0], decoder_input[0]), dim = 1).unsqueeze(0)
x = F.relu(x)
x, current_hidden_state = self.gru(x, current_hidden_state)
x = self.log_softmax(self.dense(x.squeeze(0)))
return x, current_hidden_state, aligned_weights
In this posting, we looked into how we can implement the encoder and decoder for the Seq2Seq with alignment. In the following posting, let’s see how we can train and evaluate the model. Thank you for reading.