
Recommender systems with Python - (3) Introduction to Surprise package in Python
18 Jul 2020 | Python Recommender systems Collaborative filteringIn the previous posting, we overviewed collaborative filtering (CF) and two types of CF methods - memory-based and model-based methods. In this posting, before going into the details of two CF methods, let’s have a quick look at the Surprise package in Python.
What is Surprise!?
Surprise is a Python scikit specialized for recommender systems. It provides built-in public datasets, ready-to-deploy CF algorithms, and evaluation metrics.
Installing Surprise
Installing Surprise is straightforward like any other scikit libraries. You can conveniently install it using pip. In terminal console, run below command.
pip install surprise
If you are using Google colaboratory or Jupyter Notebook, run below code in any cell.
!pip install surprise
After installation, let’s import necessary submodules for this exercise.
from surprise import Dataset
from surprise import BaselineOnly
from surprise.model_selection import cross_validate
Built-in datasets
Surprise provides built-in datasets and tools to create custom data as well. The built-in datasets provided are from MovieLens, a non-commercial movie recommendation system, and Jester, a joke recommender system. Here, let’s use the Jester built-in dataset for demonstration. For more information on Jester dataset, please refer to this page.
Load dataset
The built-in dataset can be loaded using load_builtin() function. Just type in the argument 'jester' into the function.
dataset = Dataset.load_builtin('jester')
If you haven’t downloaded the dataset before, it will ask whether you want to download it. Type in “Y” and press Enter to download.

Data exploration
You don’t need to know the details of the dataset to build a prediction model for now, but let’s briefly see how the data looks like. The raw data can be retrieved using raw_ratings attribute. Let’s print out the first two instances.
ratings = dataset.raw_ratings
print(ratings[0])
print(ratings[1])
The first two elements in each instance refer to the user ID and joke ID, respectively. The third element shows ratings and I honestly don’t know about the fourth element (let me know if you do!). Therefore, the first instance shows User #1’s rating information for Joke #5.
('1', '7', -9.281, None)
Now let’s see how many users, items, and rating records are in the dataset.
print("Number of rating instances: ", len(ratings))
print("Number of unique users: ", len(set([x[0] for x in ratings])))
print("Number of unique items (jokes): ", len(set([x[1] for x in ratings])))
It seems that 59,132 users left 1,761,439 ratings on 140 jokes. That seems like a lot of ratings for jokes!
Number of unique users: 59132
Number of unique items (jokes): 140
Prediction and evaluation
There are a few prediction algorithms that can be readily used in Surprise. The list includes widely-used CF methods such as k-nearest neighbor and probabilistic matrix factorization.
But since we haven’t looked into the details of those methods, let’s use the BaselineOnly algorithm, which predicts “baseline estimates,” i.e., calculating ratings using just bias terms of users and items. To put it simply, it does not take into account complex interaction patterns between users and items - considers only “averaged” preference patterns pertaining to users and items. For more information on the baseline model, please refer to Koren (2010)
clf = BaselineOnly()
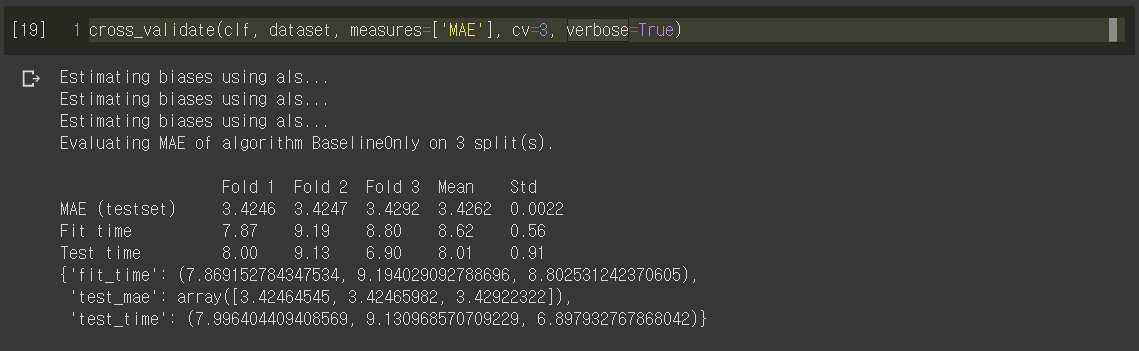
Let’s try 3-fold cross validation, which partitions the dataset into three and use different test set for each round.
cross_validate(clf, dataset, measures=['MAE'], cv=3, verbose=True)
On average, the prediction shows a mean average error (MAE) of 3.42. Not that bad, considering that we used a very naive algorithm. In the following postings, let’s see how the prediction performance will improve with more sophisticated prediction algorithms!
References
- Koren, Y. (2010). Factor in the neighbors: Scalable and accurate collaborative filtering. ACM Transactions on Knowledge Discovery from Data (TKDD), 4(1), 1-24.
- Ricci, F., Rokach, L., & Shapira, B. (2011). Introduction to recommender systems handbook. In Recommender systems handbook (pp. 1-35). Springer, Boston, MA.