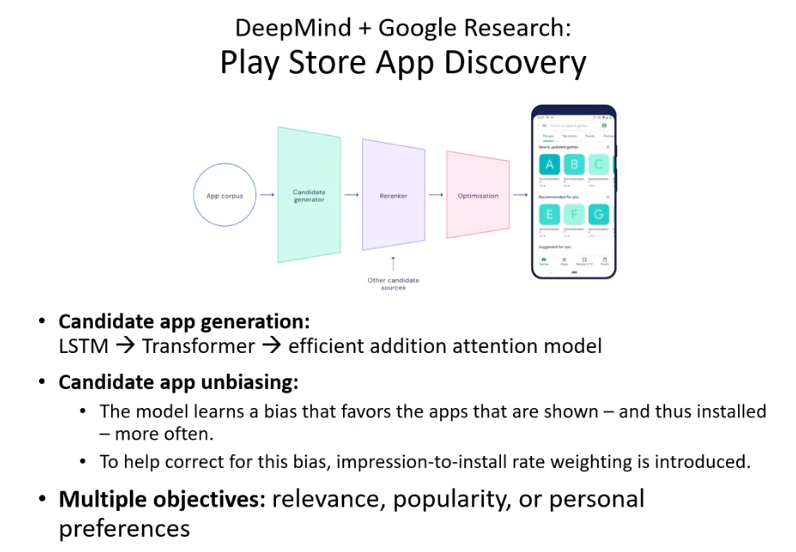
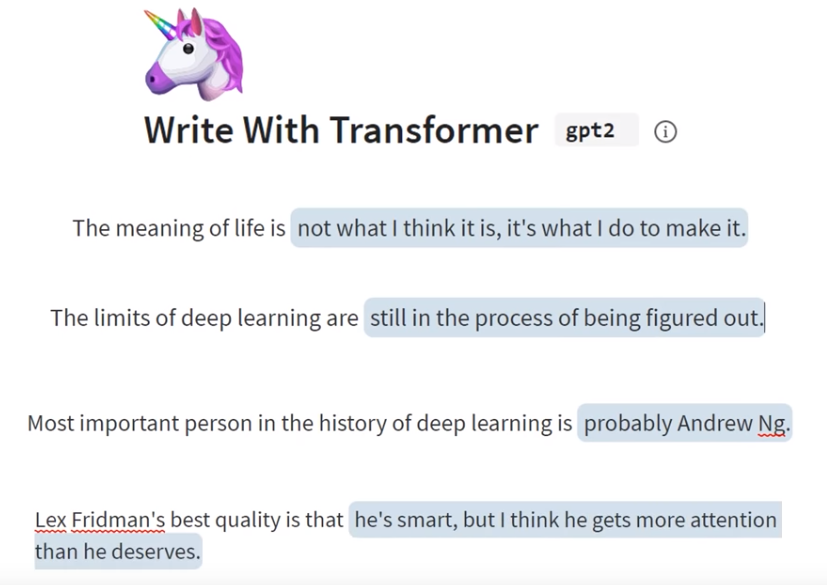
In the previous posting, we have reviewed Part 1 of Deep learning state of the art 2020 talk by Lex Fridman. In this posting, let’s review the remaining part of his talk, starting with reinforcement learning.
Deep reinforcement learning and self-play
OpenAI & Dota2
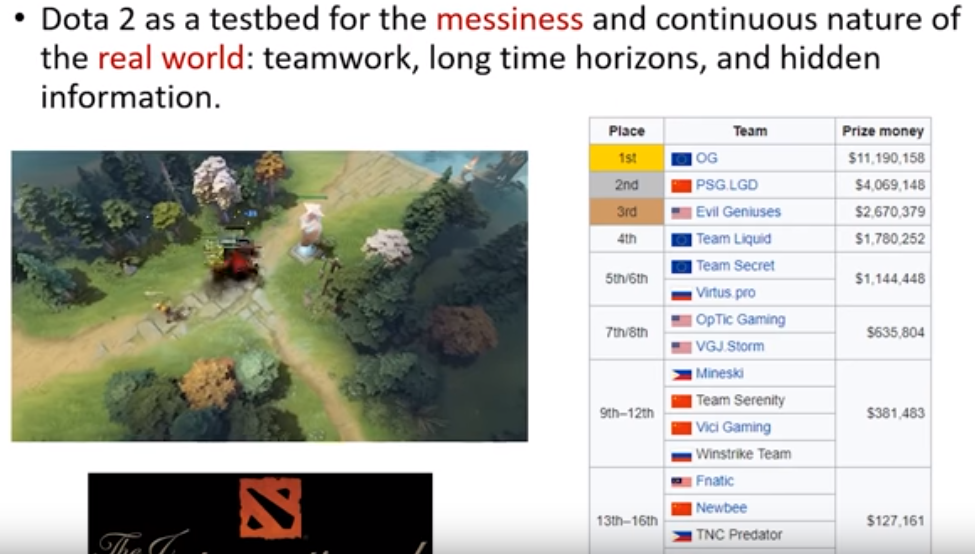
April 2019, OpenAI Five beats OG team, the 2018 world champion.
- Trained 8 time longer compared to the 2018 version
- Experienced about 45,000 yrs of self-play over 10 realtime months
- 2019 version has a 99.9% win rate vs. 2018 version
DeepMind & Quake 3 Arena Capture the Flag
Use self-play to solve the multi-agent game problem
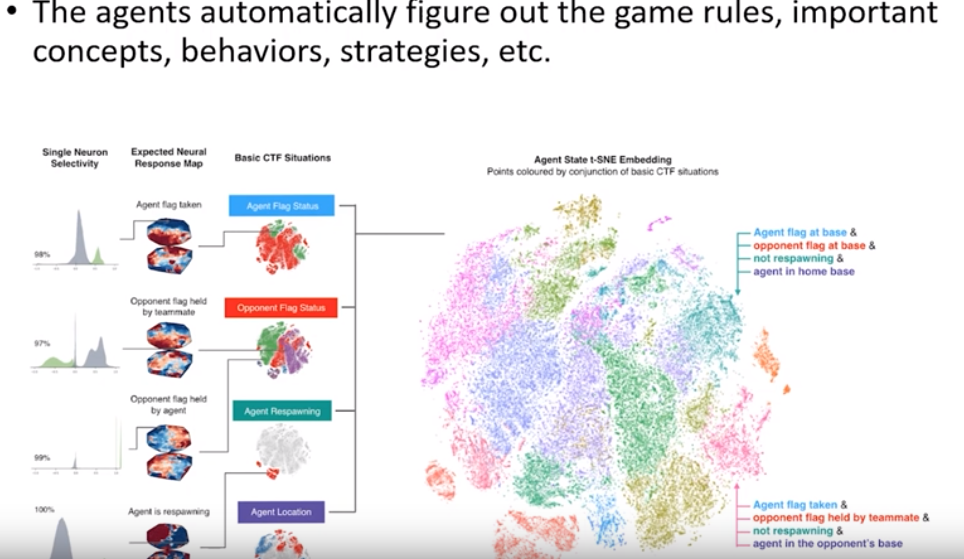
“Billions of people inhabit the planet, each with their own individual goals and actions, but still capable of coming together through teams, organisations and societies in impressive displays of collective intelligence. This is a setting we call multi-agent learning: many individual agents must act independently, yet learn to interact and cooperate with other agetns. This is an immensely difficult problem - because with co-adapting agents the world is constantly changing.”
DeepMind AlphaStar
- Dec 2018, AlphaStar beats MaNa, one of the world’s strongest professional players, 5-0
- Oct 2019, AlphaStar reaches Grandmaster level playing the game under professionally prroved conditions (for humans)
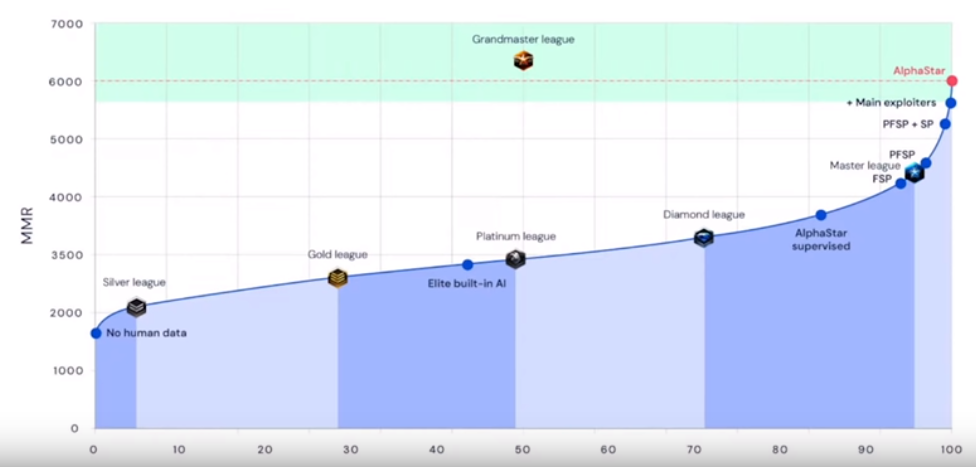
“AlphaStar is an intriguing and unorthodox player - one with the reflexes and speed of the best pros but strategies and a style that are entirely its own. The way AlphaStar was trained, with agents competing aginst each other in a league, has resulted in gameplay that’s unimaginably unusual; it really makes you question how much of StarCraft’s diverse possibilities pro players have really explored.” - Kelazhur, professional StarCraft 2 player
Pluribus - Texas Hold’em Poker
Pluribus won in six-player no-limit Texas Hold’em Poker
- Imperfect information
- Multi-agent
Offline
Self-play to generate coarse-grained “blueprint” strategy
Online
Use search to improve blueprint strategy based on particular situation
“Its major strength is its ability to use mixed strategies. That’s the same thing that humans try to do. It’s a matter of execution for humans - to do this in a perfectly random way and to do so consistently. Most people just can’t” - Darren Elias, professional Poker player
OpenAI Rubik’s Cube Manipulation

- Automatic Domain Randomization (ADR): generate progressively more difficult environment as the system learns (alternative for self-play)
- “Emergent meta-learning”: the capacity of the environment is unlimited, while the network is constrained
Hopes for 2020
Robotis
Use of RL methods in manipulation and real-world interaction tasks
Human behavior
Use of multi-agent self-play to explore naturally emerging social behaviors as a way to study equivalent multi-human systems
Games
Use RL to assist human experts in discovering new strategies at games and other tasks in simulation
Science of Deep Learning
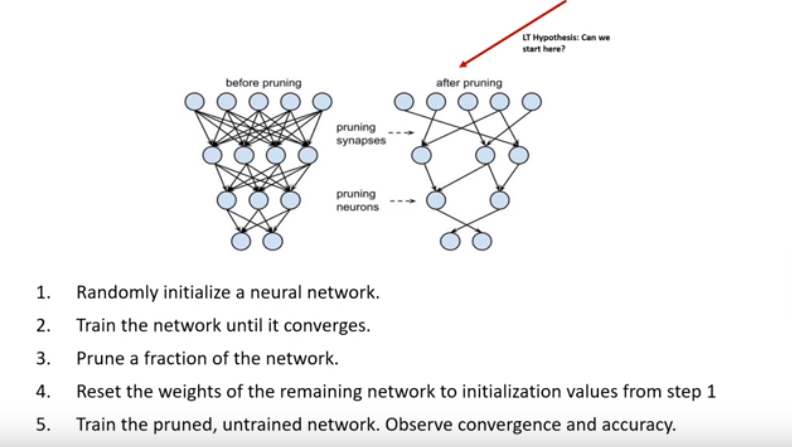
The Lottery Ticket Hypothesis
For every network, there is a subnetwork that can achieve a same level of accuracy after training. There exist architectures that are much more efficient!
“Based on these results, we articulate the lottery ticket hypothesis: dense, randomly-initialized, feed-forward networks contain subnetworks (winning tickets) that — when trained in isolation — reach test accuracy comparable to the original network in a similar number of iterations.” - Frankle and Carbin (2019)
Disentanglaed Representations
Unsupervised learning of disentagled representations without inductive biases is impossible. So inductive biases (assumptions) should be made explicit.
” Our results suggest that future work on disentanglement learning should be explicit about the role of inductive biases and (implicit) supervision, investigate concrete benefits of enforcing disentanglement of the learned representations, and consider a reproducible experimental setup covering several data sets.” - Locatello et al. (2019)
Deep Double Descent
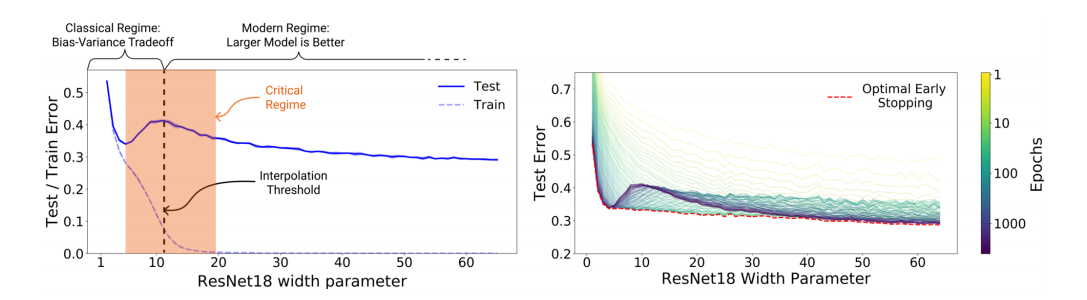
“We show that a variety of modern deep learning tasks exhibit a “double-descent” phenomenon where, as we increase model size, performance first gets worse and then gets better. Moreover, we show that double descent occurs not just as a function of model size, but also as a function of the number of training epochs. We unify the above phenomena by defining a new complexity measure we call”
Hopes for 2020
Fundamentals
Exploring fundamentals of model selection, train dynamics, and representation characteristics with respect to architecture characteristics.
Graph neural networks
Exploring use of graph neural networks for combinatorial optimization, recommender systems, etc.
Bayesian deep learning
Exploring Bayesian neural networks for estimating uncertainty and online/incremental learning
Autonomous Vehicles and AI-assited driving
Waymo
Level-4 autonomous vehicles - machine is responsible
- On-road: 20M miles
- Simulation: 10B miles
- Testing & validation: 20,000 classes of structured tests
- Initiated testing without a safety driver
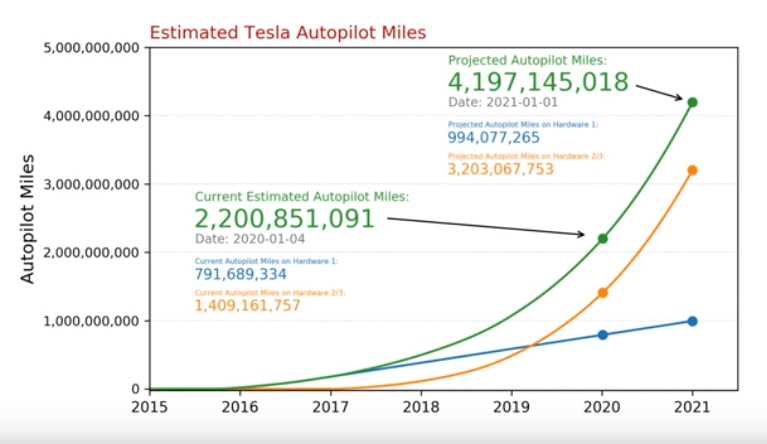
Tesla Autopilot
Level-2 autonomous vehicles - human is responsible
- Over 900k vehicle deliveries
- Currently about 2.2B estiamted Autopilot miles
- Projected Autopilot miles of 4.1B by 2021
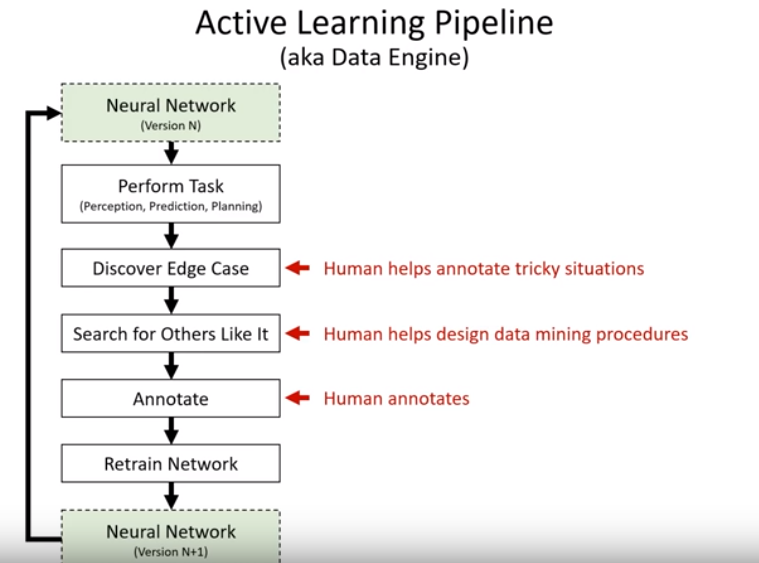
Active learning & multi-task learning
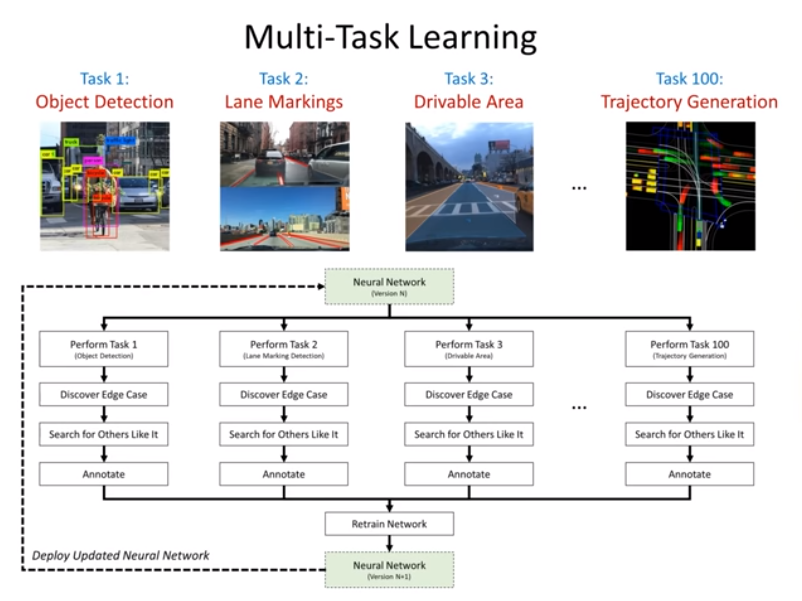
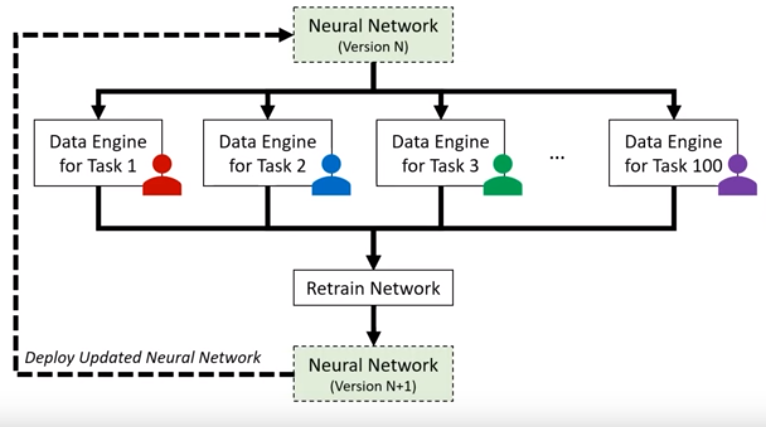
- Collaborative Deep Learning (aka Software 2.0 Engineering)
Role of human experts - train the neural network and identify edge cases that can maximize the improvement
Vision vs. Lidar (Level 2 vs. Level 4)
Level 2 - Vision sensors + DL
- Pros
- Highest resolution information
- Feasible to collect data at scale and learn
- Roads are designed for human eyes
- Cheap
- Cons
- Needs a huge amount of data to be accurate
- Less explainable
- Driver must remain vigilant
Level 3 - Lidar + Maps
- Pros
- Explainable, consistent
- Accurate with less data
- Cons
- Less amenable to ML
- Expensive (for now)
- Safety driver or teleoperation fallback
Hopes for 2020
Applied deep learning innovation
Life-long learning, active learning, multi-task learning
Over-the-air updates
More level 2 systems begin both data collection and over-the-air software updates
Public datasets of edge-cases
More publicly available datasets of challenging cases
Simulators
Improvement of publicly available simulators (CARLA, NVIDIA DRIVE Constellation, Voyage Deepdrive)
Less hype
More balanced in-depth reporting (by journalists and companies) on successes and challenges of autonomous vehicle development.
So far, we looked into deep reinforcement learning, science of deep learning, and autonomous driving parts of the talk. In the next posting, let’s examine the remaining part of the talk.