케라스와 함께하는 쉬운 딥러닝 (15) - 순환형 신경망(RNN) 기초
25 Jun 2019 | Python Keras Deep Learning 케라스순환형 신경망 1 - RNN 구조 기초
Objective: RNN의 기본적인 구조를 이해하고 케라스로 이를 구현해본다
MLP나 CNN와 같은 feedforward net과는 달리, RNN은 순차형(sequential) 데이터를 모델링하는데 최적화된 구조라고 할 수 있다. 데이터가 입력되는 순서가 중요한 역할을 하는 순차형 정보를 수월하게 처리하기 위해 RNN은 이전 상태(state)를 기록하고 이를 다음 셀에서 활용할 수 있는 독특한 구조를 가지고 있다.
그러므로, RNN을 효과적으로 활용하기 위해서는 이러한 상태(state)들 간의 순서(sequence)라는 컨셉을 이해하는 것이 필수적이다.
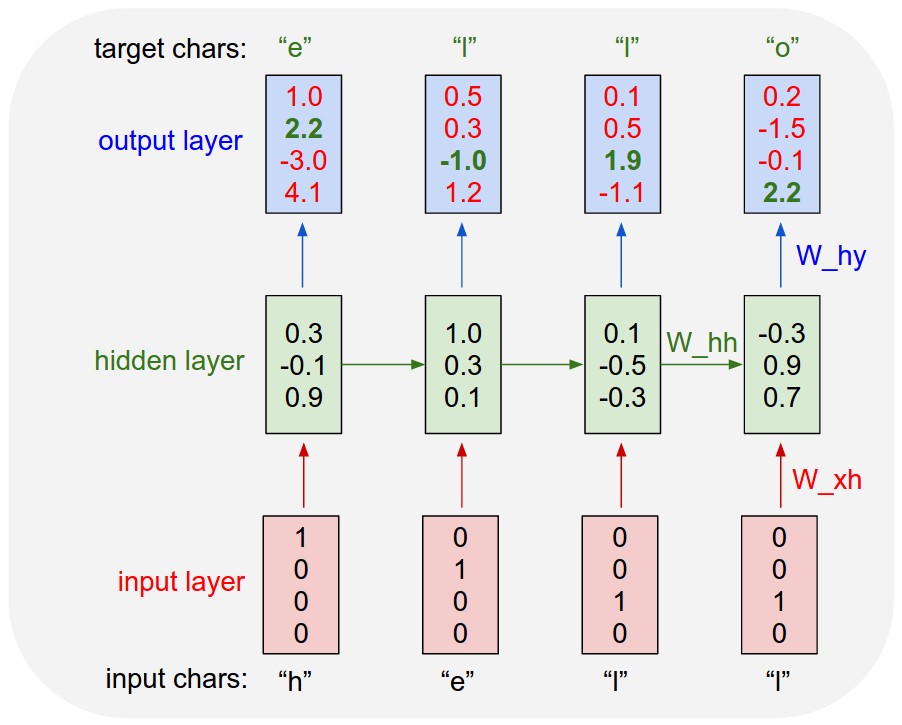
RNN 모델 입력 데이터
가장 기본적인 형태의 RNN 셀에 입력되는 텐서의 모양은 (batch_size, timesteps, input_dim)와 같다.
batch_size: 경사하강법(stochastic gradient descent)으로 모델이 학습될 때 한 번에 고려되는 데이터 인스턴스의 갯수. RNN 셀을 생성할 때에는 설정되지 않고 주로 모델을 fitting하는 과정에서 설정된다.timesteps: 인풋 시퀀스의 갯수input_dim: 각 인풋 시퀀스의 차원(dimensionality). feedforward net에서 입력 feature의 차원 수와 비슷한 역할을 한다고 볼 수 있다.
# RNN 입력 데이터 예시
x = np.array([[
[1, # => input_dim 1
2, # => input_dim 2
3], # => input_dim 3 # => timestep 1
[4, 5, 6] # => timestep 2
], # => batch 1
[[7, 8, 9], [10, 11, 12]], # => batch 2
[[13, 14, 15], [16, 17, 18]] # => batch 3
])
print('(Batch size, timesteps, input_dim) = ',x.shape)
(Batch size, timesteps, input_dim) = (3, 2, 3)
SimpleRNN
SimpleRNN은 가장 기본적인 형태의 RNN 셀로, 입력 텐서에는 최소 2개의 파라미터(timesteps, input_dim)을 설정을 해주어야 한다
# rnn = SimpleRNN(50)(Input(shape = (10,))) => error
# rnn = SimpleRNN(50)(Input(shape = (10, 30, 40))) => error
rnn = SimpleRNN(50)(Input(shape = (10, 30)))
return_sequences 파라미터를 따로 설정해 주지 않으면 False로 디폴트 값이 설정되며, 이 경우에는 출력 값이 셀의 갯수(number of cells)와 동일하다. 즉, 셀 하나당 하나의 스칼라(scalar) 값이 반환된다.
rnn = SimpleRNN(50)(Input(shape = (10, 30)))
print(rnn.shape)
(?, 50)
만약 return_sequences 파라미터를 True로 설정해 주면 출력 값은 (timesteps X Num_cells)가 되며 timesteps은 입력 텐서의 모양에 따라 결정된다.
rnn = SimpleRNN(50, return_sequences = True)(Input(shape = (10, 30)))
print(rnn.shape)
(?, ?, 50)
좀더 자세히 예시를 통해 살펴보자
return_sequences == False인 경우
rnn = SimpleRNN(50, return_sequences = False, return_state = True)(Input(shape = (10, 30)))
print(rnn[0].shape) # shape of output
print(rnn[1].shape) # shape of last state
(?, 50)
(?, 50)
return_sequences == True인 경우
rnn = SimpleRNN(50, return_sequences = True, return_state = True)(Input(shape = (10, 30)))
print(rnn[0].shape) # shape of output
print(rnn[1].shape) # shape of last state
(?, ?, 50)
(?, 50)
이번 포스팅에서는 RNN의 상태(sequence)와 순서(sequence)의 개념에 대해서 알아보고, 기본적인 RNN 셀(SimpleRNN)을 케라스를 통해 어떻게 생성하고 설정하는 지에 대해서 알아보았다. 다음 포스팅에서는 보다 진보된 형태의 RNN 구조에 대해서 알아보자.
전체 코드
본 실습의 전체 코드는 여기에서 열람하실 수 있습니다!