
케라스와 함께하는 쉬운 딥러닝 (11) - CNN 모델 개선하기 2
05 May 2018 | Python Keras Deep Learning 케라스합성곱 신경망 5 - CNN 모델 개선하기 2
Objective: 케라스로 개선된 CNN 모델을 만들어 본다.
지난 포스팅에서 케라스로 deep CNN 모델을 만들어 보았지만, MNIST 데이터 셋에서 간단한 cnn 모델에 비해 오히려 학습이 잘 되지 않고, 정확도가 떨어지는 경향을 보여주었다.
이번 포스팅에서는 지난 포스팅의 깊은 cnn 모델의 학습 결과를 개선해 보고, 새로운 cnn 모델을 시도해 보자.
Deep CNN - 2
MLP 모델을 개선하기 위해 사용했던 방법들을 Deep CNN 모델을 개선하기 위해서도 적용해 보자.
- 가중치 초기화(Weight initialization)
- 배치 정규화(Batch Normalization)
- 드랍아웃(Dropout)
MNIST 데이터 셋 불러오기
MLP에서도 사용했던 MNIST 데이터 셋을 불러온다. 그때와 다른 점이 있다면, 그때는 MLP 모델에 입력하기 위해 (28, 28, 1) 짜리 사이즈의 데이터를 flatten해 784차원의 1차원 벡터로 만들었다면, 여기에서는 3차원 이미지 데이터를 그대로 사용한다는 것이다.
import numpy as np
import matplotlib.pyplot as plt
from keras.datasets import mnist
from keras.utils.np_utils import to_categorical
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# reshaping X data: (n, 28, 28) => (n, 28, 28, 1)
X_train = X_train.reshape((X_train.shape[0], X_train.shape[1], X_train.shape[2], 1))
X_test = X_test.reshape((X_test.shape[0], X_test.shape[1], X_test.shape[2], 1))
# converting y data into categorical (one-hot encoding)
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
(60000, 28, 28, 1), (10000, 28, 28, 1), (60000, 10), (10000, 10)
모델 생성하기
기존의 deep CNN 모델과 구조는 동일하지만 학습을 개선하기 위해 위에서 제안한 세 가지 방법(가중치 초기화, 배치 정규화, 드랍아웃)이 활용되었다.
from keras.layers import BatchNormalization, Dropout
def deep_cnn_advanced():
model = Sequential()
model.add(Conv2D(input_shape = (X_train.shape[1], X_train.shape[2], X_train.shape[3]), filters = 50, kernel_size = (3,3), strides = (1,1), padding = 'same', kernel_initializer='he_normal'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(filters = 50, kernel_size = (3,3), strides = (1,1), padding = 'same', kernel_initializer='he_normal'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size = (2,2)))
model.add(Conv2D(filters = 50, kernel_size = (3,3), strides = (1,1), padding = 'same', kernel_initializer='he_normal'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(filters = 50, kernel_size = (3,3), strides = (1,1), padding = 'same', kernel_initializer='he_normal'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size = (2,2)))
model.add(Conv2D(filters = 50, kernel_size = (3,3), strides = (1,1), padding = 'same', kernel_initializer='he_normal'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(filters = 50, kernel_size = (3,3), strides = (1,1), padding = 'same', kernel_initializer='he_normal'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size = (2,2)))
# prior layer should be flattend to be connected to dense layers
model.add(Flatten())
# dense layer with 50 neurons
model.add(Dense(50, activation = 'relu', kernel_initializer='he_normal'))
model.add(Dropout(0.5))
# final layer with 10 neurons to classify the instances
model.add(Dense(10, activation = 'softmax', kernel_initializer='he_normal'))
adam = optimizers.Adam(lr = 0.001)
model.compile(loss = 'categorical_crossentropy', optimizer = adam, metrics = ['accuracy'])
return model
model = deep_cnn_advanced()
model.summary()
배치 정규화 레이어가 추가되면서 파라미터 개수가 미묘하게 늘었지만 큰 차이는 없다.
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_34 (Conv2D) (None, 28, 28, 50) 500
_________________________________________________________________
batch_normalization_7 (Batch (None, 28, 28, 50) 200
_________________________________________________________________
activation_4145 (Activation) (None, 28, 28, 50) 0
_________________________________________________________________
conv2d_35 (Conv2D) (None, 28, 28, 50) 22550
_________________________________________________________________
batch_normalization_8 (Batch (None, 28, 28, 50) 200
_________________________________________________________________
activation_4146 (Activation) (None, 28, 28, 50) 0
_________________________________________________________________
max_pooling2d_19 (MaxPooling (None, 14, 14, 50) 0
_________________________________________________________________
conv2d_36 (Conv2D) (None, 14, 14, 50) 22550
_________________________________________________________________
batch_normalization_9 (Batch (None, 14, 14, 50) 200
_________________________________________________________________
activation_4147 (Activation) (None, 14, 14, 50) 0
_________________________________________________________________
conv2d_37 (Conv2D) (None, 14, 14, 50) 22550
_________________________________________________________________
batch_normalization_10 (Batc (None, 14, 14, 50) 200
_________________________________________________________________
activation_4148 (Activation) (None, 14, 14, 50) 0
_________________________________________________________________
max_pooling2d_20 (MaxPooling (None, 7, 7, 50) 0
_________________________________________________________________
conv2d_38 (Conv2D) (None, 7, 7, 50) 22550
_________________________________________________________________
batch_normalization_11 (Batc (None, 7, 7, 50) 200
_________________________________________________________________
activation_4149 (Activation) (None, 7, 7, 50) 0
_________________________________________________________________
conv2d_39 (Conv2D) (None, 7, 7, 50) 22550
_________________________________________________________________
batch_normalization_12 (Batc (None, 7, 7, 50) 200
_________________________________________________________________
activation_4150 (Activation) (None, 7, 7, 50) 0
_________________________________________________________________
max_pooling2d_21 (MaxPooling (None, 3, 3, 50) 0
_________________________________________________________________
flatten_11 (Flatten) (None, 450) 0
_________________________________________________________________
dense_21 (Dense) (None, 50) 22550
_________________________________________________________________
dropout_2 (Dropout) (None, 50) 0
_________________________________________________________________
dense_22 (Dense) (None, 10) 510
=================================================================
Total params: 137,510
Trainable params: 136,910
Non-trainable params: 600
_________________________________________________________________
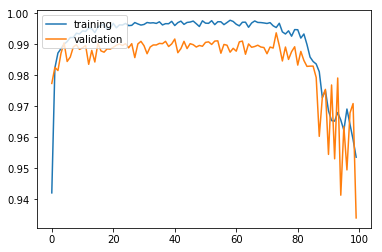
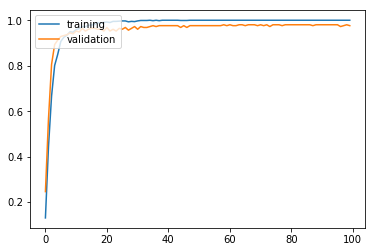
모델을 학습시키고 학습 과정을 시각화해 본다. 학습이 훨씬 안정적으로 이루어지는 것을 볼 수 있다.
history = model.fit(X_train, y_train, batch_size = 50, validation_split = 0.2, epochs = 100, verbose = 0)
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.legend(['training', 'validation'], loc = 'upper left')
plt.show()
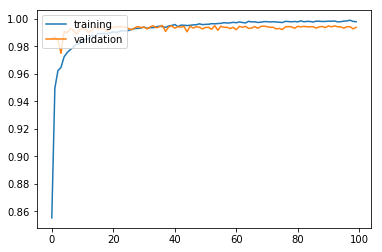
학습 결과를 검증해 본다.
results = model.evaluate(X_test, y_test)
print('Test accuracy: ', results[1])
Test accuracy: 0.9942
최종 검증 정확도 99.42%로 기존의 모델에 비해 훨씬 개선된 성능을 보여준다.
Deep CNN - 3
방금 생성한 모델로도 99%가 넘는 성능을 보여주며 이미지 데이터를 처리함에 있어 CNN 구조가 얼마나 효과적인지를 입증하였다. 이번에는 색다른 CNN 구조를 시도해 보자.
Network In Network (NIN)
처음에 Deep CNN에 대해서 소개할 때, 모델이 깊어지고 레이어의 수가 많아질수록 추정해야 할 파라미터의 개수가 많아져 연산량이 늘어나고 학습이 오래걸린다고 언급하였다.
바로 위의 모델에서 MLP를 개선하기 위한 방법들을 CNN에도 적용하며 학습 과정을 개선하는 데에는 성공하였다. 이번에는 깊어진 CNN에서 파라미터 개수를 줄이기 위한 방법 중 하나로 “Network In Network (NIN)”을 적용해 보자.
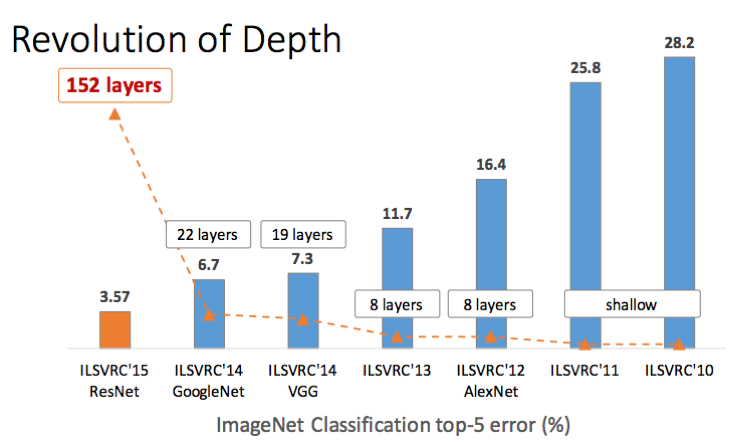
NIN은 1x1 convolution이라고도 하며, Min et al 2013이 제안하였다. 방법은 매우 간단하다. convolution layer 다음에 pooling layer가 아닌 convolution layer를 연속해서 쌓는것이다. 너무 단순해서 비상식적으로 보일 수도 있는데, 직관적으로는 입력 공간의 차원을 축소하여 앞서 얘기했듯이 파라미터 개수를 이전에 비해 상당히 줄일 수 있다.
![]()
2015년에 제안된 구글넷(GoogleNet)의 인셉션 구조는 1x1 convolution을 적극 사용해 파라미터 개수를 획기적으로 줄이는 데 성공하였다.

모델 생성하기
모델 생성은 크게 복잡할 것 없다. 기존의 convolution layer에 1x1 convolution layer를 붙이면 된다.
def deep_cnn_advanced_nin():
model = Sequential()
model.add(Conv2D(input_shape = (X_train.shape[1], X_train.shape[2], X_train.shape[3]), filters = 50, kernel_size = (3,3), strides = (1,1), padding = 'same', kernel_initializer='he_normal'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(filters = 50, kernel_size = (3,3), strides = (1,1), padding = 'same', kernel_initializer='he_normal'))
# 1x1 convolution
model.add(Conv2D(filters = 25, kernel_size = (1,1), strides = (1,1), padding = 'valid', kernel_initializer='he_normal'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size = (2,2)))
model.add(Conv2D(filters = 50, kernel_size = (3,3), strides = (1,1), padding = 'same', kernel_initializer='he_normal'))
# 1x1 convolution
model.add(Conv2D(filters = 25, kernel_size = (1,1), strides = (1,1), padding = 'valid', kernel_initializer='he_normal'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(filters = 50, kernel_size = (3,3), strides = (1,1), padding = 'same', kernel_initializer='he_normal'))
# 1x1 convolution
model.add(Conv2D(filters = 25, kernel_size = (1,1), strides = (1,1), padding = 'valid', kernel_initializer='he_normal'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size = (2,2)))
model.add(Conv2D(filters = 50, kernel_size = (3,3), strides = (1,1), padding = 'same', kernel_initializer='he_normal'))
# 1x1 convolution
model.add(Conv2D(filters = 25, kernel_size = (1,1), strides = (1,1), padding = 'valid', kernel_initializer='he_normal'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(filters = 50, kernel_size = (3,3), strides = (1,1), padding = 'same', kernel_initializer='he_normal'))
# 1x1 convolution
model.add(Conv2D(filters = 25, kernel_size = (1,1), strides = (1,1), padding = 'valid', kernel_initializer='he_normal'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size = (2,2)))
# prior layer should be flattend to be connected to dense layers
model.add(Flatten())
# dense layer with 50 neurons
model.add(Dense(50, activation = 'relu', kernel_initializer='he_normal'))
model.add(Dropout(0.5))
# final layer with 10 neurons to classify the instances
model.add(Dense(10, activation = 'softmax', kernel_initializer='he_normal'))
adam = optimizers.Adam(lr = 0.001)
model.compile(loss = 'categorical_crossentropy', optimizer = adam, metrics = ['accuracy'])
return model
model = deep_cnn_advanced_nin()
model.summary()
아래 summary에서 보듯이 학습 가능한 파라미터의 수를 기존의 13만여개에서 8만여개로 60% 수준으로 줄일 수 있었다.
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_45 (Conv2D) (None, 28, 28, 50) 500
_________________________________________________________________
batch_normalization_13 (Batc (None, 28, 28, 50) 200
_________________________________________________________________
activation_4151 (Activation) (None, 28, 28, 50) 0
_________________________________________________________________
conv2d_46 (Conv2D) (None, 28, 28, 50) 22550
_________________________________________________________________
conv2d_47 (Conv2D) (None, 28, 28, 25) 1275
_________________________________________________________________
batch_normalization_14 (Batc (None, 28, 28, 25) 100
_________________________________________________________________
activation_4152 (Activation) (None, 28, 28, 25) 0
_________________________________________________________________
max_pooling2d_24 (MaxPooling (None, 14, 14, 25) 0
_________________________________________________________________
conv2d_48 (Conv2D) (None, 14, 14, 50) 11300
_________________________________________________________________
conv2d_49 (Conv2D) (None, 14, 14, 25) 1275
_________________________________________________________________
batch_normalization_15 (Batc (None, 14, 14, 25) 100
_________________________________________________________________
activation_4153 (Activation) (None, 14, 14, 25) 0
_________________________________________________________________
conv2d_50 (Conv2D) (None, 14, 14, 50) 11300
_________________________________________________________________
conv2d_51 (Conv2D) (None, 14, 14, 25) 1275
_________________________________________________________________
batch_normalization_16 (Batc (None, 14, 14, 25) 100
_________________________________________________________________
activation_4154 (Activation) (None, 14, 14, 25) 0
_________________________________________________________________
max_pooling2d_25 (MaxPooling (None, 7, 7, 25) 0
_________________________________________________________________
conv2d_52 (Conv2D) (None, 7, 7, 50) 11300
_________________________________________________________________
conv2d_53 (Conv2D) (None, 7, 7, 25) 1275
_________________________________________________________________
batch_normalization_17 (Batc (None, 7, 7, 25) 100
_________________________________________________________________
activation_4155 (Activation) (None, 7, 7, 25) 0
_________________________________________________________________
conv2d_54 (Conv2D) (None, 7, 7, 50) 11300
_________________________________________________________________
conv2d_55 (Conv2D) (None, 7, 7, 25) 1275
_________________________________________________________________
batch_normalization_18 (Batc (None, 7, 7, 25) 100
_________________________________________________________________
activation_4156 (Activation) (None, 7, 7, 25) 0
_________________________________________________________________
max_pooling2d_26 (MaxPooling (None, 3, 3, 25) 0
_________________________________________________________________
flatten_13 (Flatten) (None, 225) 0
_________________________________________________________________
dense_25 (Dense) (None, 50) 11300
_________________________________________________________________
dropout_3 (Dropout) (None, 50) 0
_________________________________________________________________
dense_26 (Dense) (None, 10) 510
=================================================================
Total params: 87,135
Trainable params: 86,785
Non-trainable params: 350
_________________________________________________________________
history = model.fit(X_train, y_train, batch_size = 50, validation_split = 0.2, epochs = 100, verbose = 0)
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.legend(['training', 'validation'], loc = 'upper left')
plt.show()
모델의 학습 과정은 deep CNN -2 와 크게 다르지 않아 보인다.
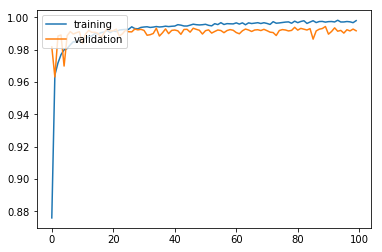
results = model.evaluate(X_test, y_test)
print('Test accuracy: ', results[1])
Test accuracy: 0.9914
최종 검증 정확도도 99.14%로 두 번째 깊은 CNN 모델에 비해 크게 다르지 않다. 하지만 파라미터의 수를 상당히 줄였음에도, 비슷한 정확도가 나온다는 데에서 1x1 convolution을 가치를 찾을 수 있다고 할 수 있다.
많은 딥 러닝 연구가 이미지/영상 분석과 함께 맥을 이어 왔고, 이에 따라 NIN과 같이 기존의 vanilla cnn 구조를 개선하기 위한 연구들이 지금도 수없이 제안되고 있다. 최근에 본 책에 따르면 알버트 아인슈타인이나 베누아 망델브로와 같은 천재들은 이 세상 대부분의 것들을 “이미지(image)”로 인식했으며, 천재가 아니더라도 대부분의 사람들은 글자나 수식, 그리고 기억까지도 뇌에서 이미지로 인지한다고 한다. 이미지 분석과 딥 러닝과 관련된 연구가 앞으로 더욱 기대되는 이유 중 하나이다.
전체 코드
본 실습의 전체 코드는 여기에서 열람하실 수 있습니다!
 </p>
</p>
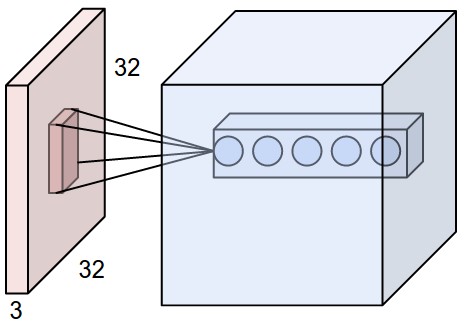
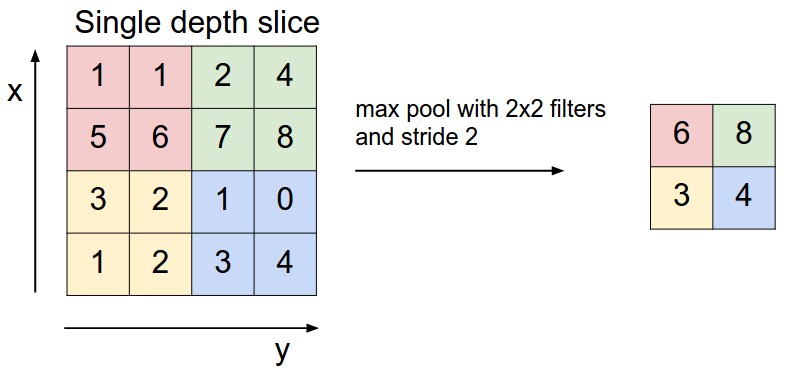


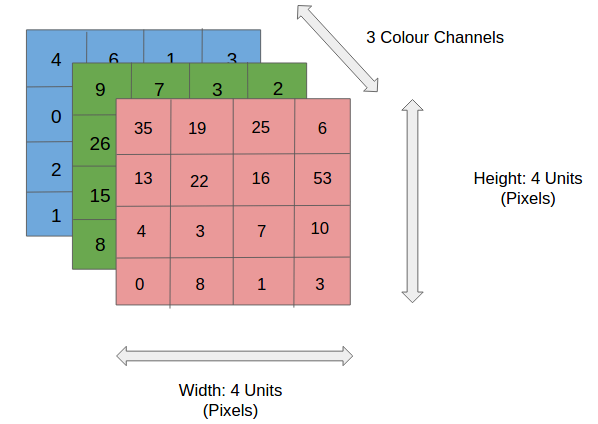

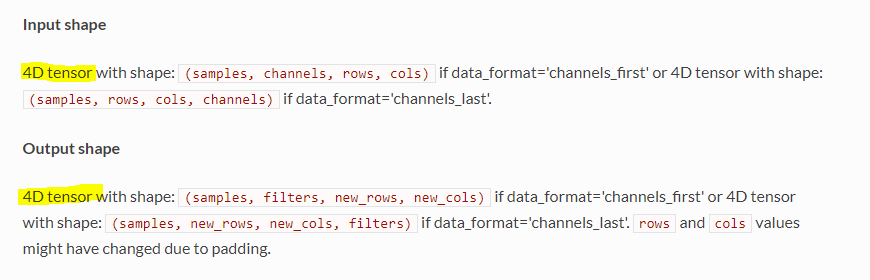 Keras Conv2D 레이어의 입력과 출력
Keras Conv2D 레이어의 입력과 출력