Using external fonts in Google Colaboratory (Google colab에서 한글 폰트 사용하기)
27 Apr 2018 | Python Colab ColaboratoryUsing external fonts in Google colaboratory
In most cases, it is enough to use default font in Python programming, especially you are using English. But, mostly when visualizing results, languages other than English are to be used for the sake of communication, and you would like to use non-default fonts in Python.
When you are using local IDEs like PyCharm or Jupyter Notebook, this is not a difficult issue. You could just install font in your environment, and just let the visualization library (e.g., matplotlib) to know where the installed font in located.
However, when using Google Colab, this is kind of tricky as you do not use local runtime environment most of the time. Instead, you run Python program in the Ubuntu environment provided by the server. So, another way to install and use the external font should be employed to operate.
In this posting, I show you one of the easy way to solve this problem. I have made the example with one of the Korean fonts provided by Google (Noto Sans CJK KR), but if you just change the url and the name of font, you could virtually use any font you want!
0. Using other languages in colab without installation
When I tried using Korean without installation, the result looked like this.
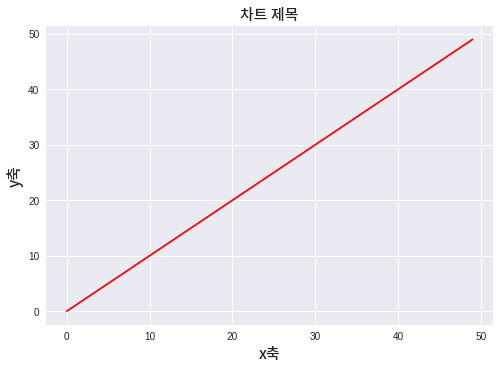
In the end, this chart will look like below (sorry for non-korean guys). Now let’s look at the procedure step by step.
1. Obtain the source (url) of the font
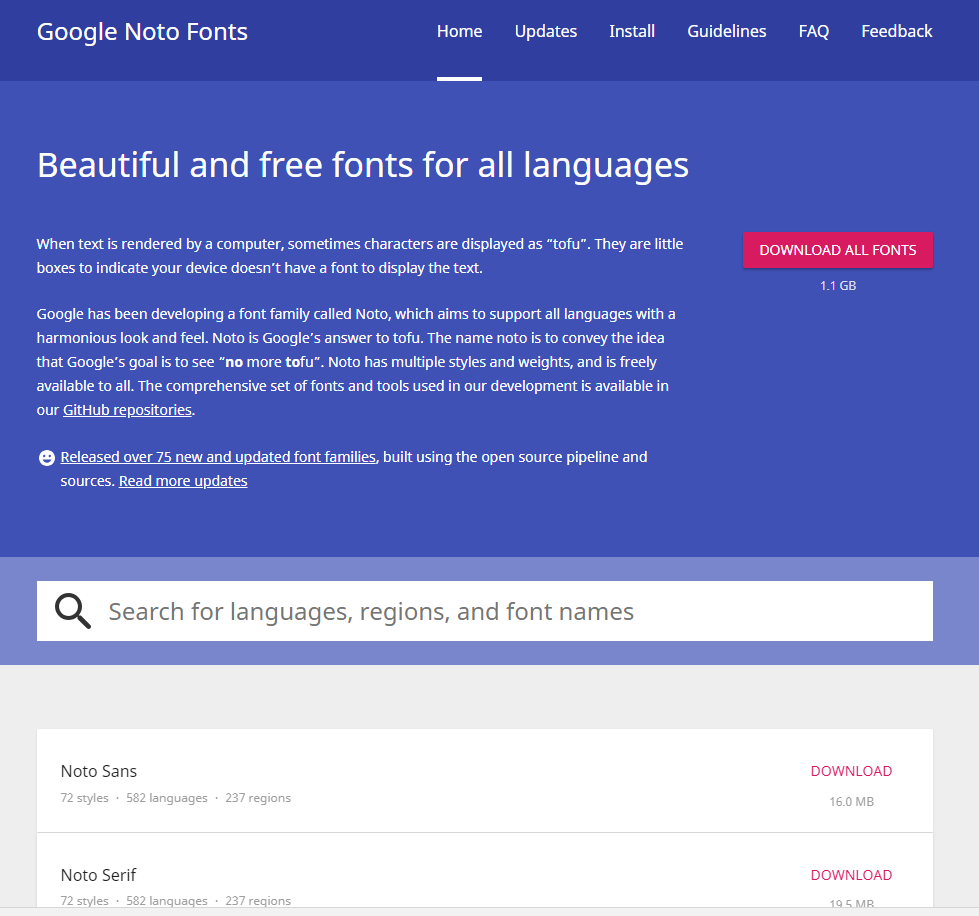
To start with, you wil have to obtain the source of the external font you are trying to use. In my case, I will use Noto Sans font provided by Google.
You could find Google Noto Fonts here
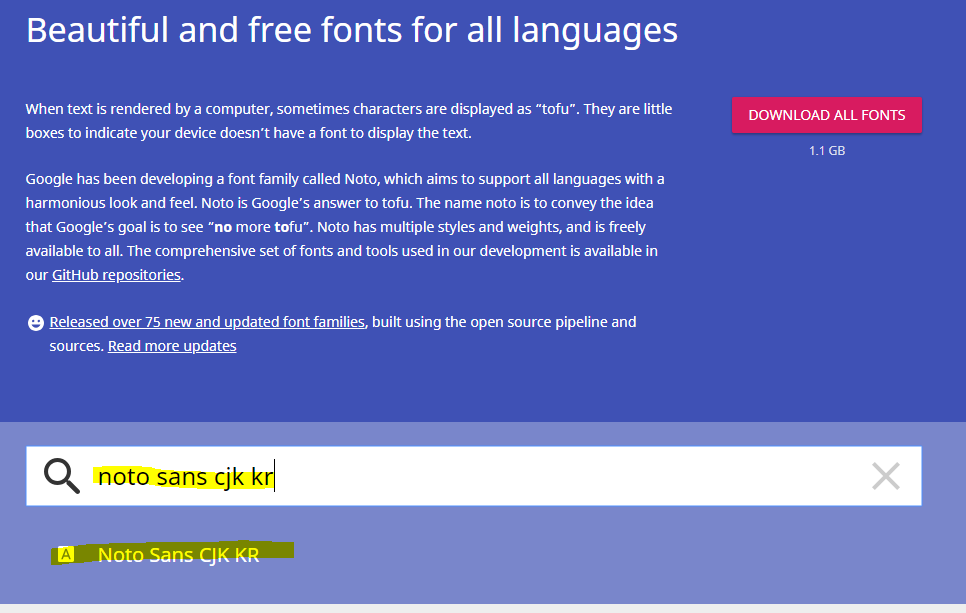
First, search for the font that you are going to use. As I mentioned, I have used Noto Sans CJK KR for my Korean letters.
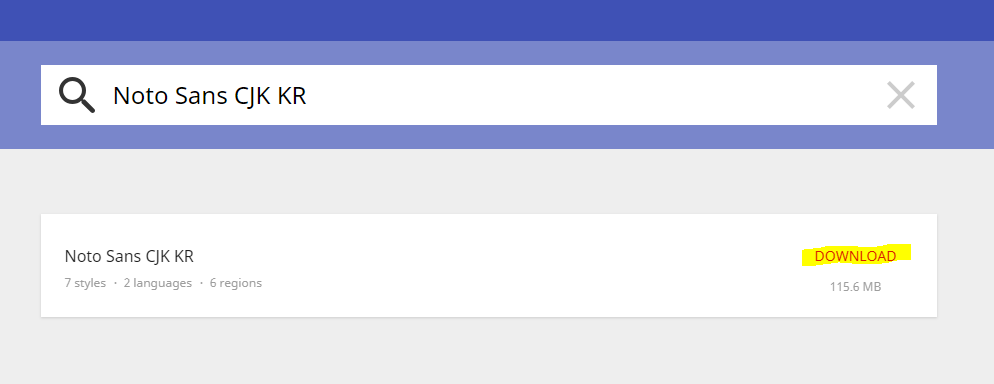
Then, download and check if this is the font that you are going to use. And check the file names (mostly .otf or ttf for fonts) and remeber them. The name of the font file that I am going to use is NotoSansCJKkr-Medium.otf. Also, remember the download link of the zip file. In my case, it is https://noto-website-2.storage.googleapis.com/pkgs/NotoSansCJKkr-hinted.zip
3. Download font files
Now, open a google colab file and start coding. We are going to use google colab like a Ubuntu terminal for the moment. So, Ubuntu commands such as wget, mv, unzip are going to be used.
To start with, download the zip file (in this case, NotoSansCJKkr-hinted.zip) that contains font files.
!wget "source_of_your_target_file"

4. Unzip font files
As you have checked, font files are contained in a zip file (.zip), so you have to unzip the file to get the font files. Use !unzip command to open the zip file.
Note that if you have downloaded font file itself (i.e., not zipped), you do not have to unzip them.
!unzip "your_file_name.zip"

5. Move font files
Now, move your font file to the font directory in Ubuntu environment. Use !mv command to move the file. In most cases you will get to move your font to /usr/share/fonts/truetype. Note that this will not do anything with your local environment!!!
!mv "your_font_file_name" "font_directory"
In my case,
!mv NotoSansCJKkr-Medium.otf /usr/share/fonts/truetype/
6. Test if it works properly
Now the installation is finished. I will test by using installed Korean font in drawing a chart with matplotlib libary.
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
# fetch the name of font that was installed
path = '/usr/share/fonts/truetype/your_font_name'
fontprop = fm.FontProperties(fname=path)
In my case, I have used below code.
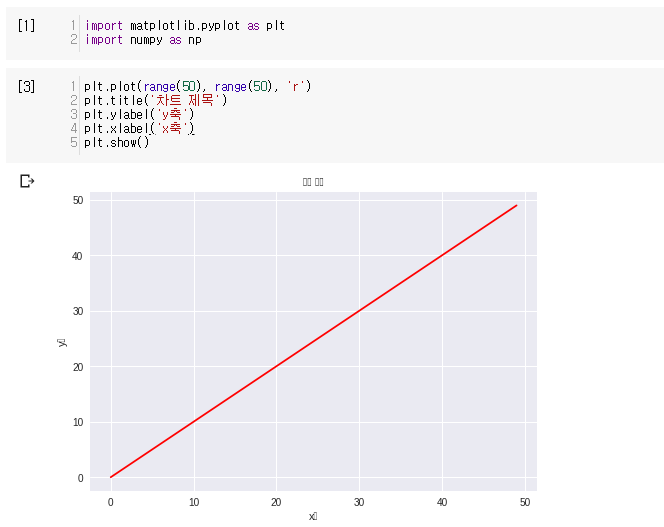
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
path = '/usr/share/fonts/truetype/NotoSansCJKkr-Medium.otf'
fontprop = fm.FontProperties(fname=path, size= 15)
plt.plot(range(50), range(50), 'r')
plt.title('차트 제목', fontproperties=fontprop)
plt.ylabel('y축', fontproperties=fontprop)
plt.xlabel('x축', fontproperties=fontprop)
plt.show()
Code
Code in this post can be exhibited by below link. link